

Inferential Statistics:
In inferential statistics, we use a randomly selected sample data to describe and make inferences about the population. Therefore, the resulting values are approximate values but not accurate values.
Need for inferential statistics:
Dealing with population is not that easy as it sounds. It is practically not possible to make a complete census of a population, because in the real world we may come across many constraints like time, budget etc. To have a better understanding of inferential statistics, one must have knowledge about the basic terms used in statistics.
Prerequisites:
Probability:
Probability is defined as the ratio of number of favored outcomes with the total number of possible outcomes. i.e. (Probability) P = Number of favored outcomes/ total number of possible outcomes.
Basic formulas:
- Addition rule:
P (A or B) = P (A) + P (B) – P (A and B) If A and B are mutually exclusive i.e., either A or B can occur, but not both.
- Multiplication rule:
P (A and B) = P (A) * P (B) Only if and B are independent i.e., occurrence of event A does not affect the occurrence of event B.
- Permutation:
nPr = n! / (n-r)!
- Combination:
nCr = n! / r! (n-r)!
where,
n - total number of objects
r - number of objects taken at a time
Note:
- Where do we use permutations and combinations: To find the number of ways to arrange or select from a list of items or list of people etc.
- Difference between permutation and combination: Permutation is used when the order of selecting the items matters. Combination is used when the order of selecting items does not make any difference.
Example1:
Suppose you have 4 books B1, B2, B3, and B4 to arrange in a book shelf. Find the number of ways you can arrange these books on the shelf.
Answer:
Here, n (total number of objects) = 4
r (number of objects taken at a time) = 4
nPr = 4P4 = 4! / (4-4)! = 4*3*2*1/1 = 24
Example 2:
There are 10 students in a class, only 4 students can be selected for an event. Find the number of ways to select the 4 students.
Answer:
Here, n (total number of objects) = 10
r (number of objects taken at a time) = 4
nCr = 10C4 = 10! / (4!) *(10-4)! = 10*9*8*7/ 4*3*2*1 = 210
Random variable:
A random variable is a variable that holds the number of possible outcomes of an event.
Example1:
Consider an event where a dice is rolled, what are the possible values that a random variable holds for an event of getting an even number.
Answer:
Let x be the random variable, x = {0, 1, 2, 3, 4}
Types of random variables:
- Discrete random variable: A variable is said to be discrete random variable if, all the values it is holding are discrete
Example:
A die is rolled; consider possible events for getting an odd number.
Answer:
let x be the random variable, x = {0, 1, 2, 3}
Continuous random variable: A variable is said to be continuous random variable if it is holding continuous values.
Example:
height of all students in a class is measured. Consider the possible values of student’s height are between 5-6 inches.
Answer:
let x be a random variable, x = {5.1, 5.2……. 5.9}
Probability distribution:
Probability distribution is representation of data in any form like table, bar chart etc., which tells us about the probability of an event for all possible values.
1. Table:
When a die is rolled,
Let x = event
P(x) = probability for event x to happen
|
X |
P(x) |
|
Probability of getting 1 |
1/6 |
|
Probability of getting an even number |
3/6 |
|
Probability of getting a prime number |
3/6 |
|
Probability of getting factors of 6 |
4/6 |
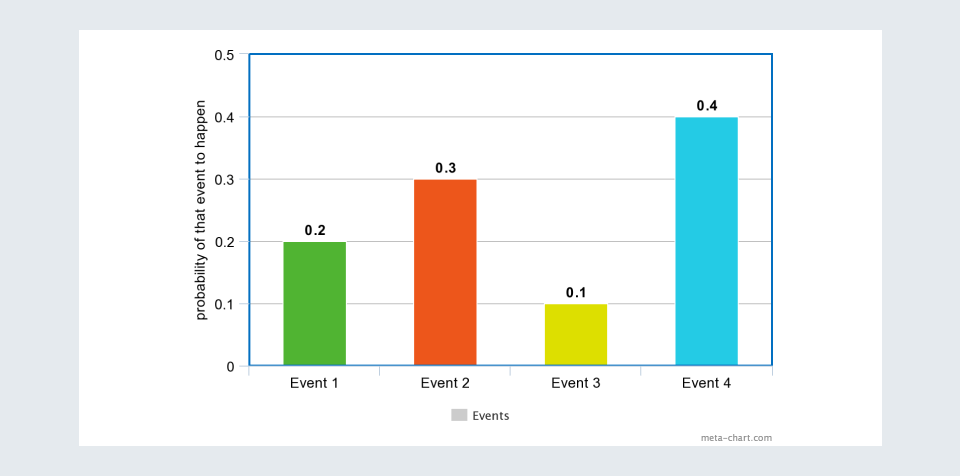
2. Bar chart:
Assume there 2 green balls, 3 orange balls, 1 yellow ball, and 4 blue balls in a bag.
Let,
Event 1 = probability of getting a green ball
Event 2 = probability of getting an orange ball
Event 3 = probability of getting a yellow ball
Event 4 = probability of getting a blue ball
Expected value /Mean value /average E(x):
Expected value is the sum of product of possible event and it’s probability of occurrence.
E(x) = x1*P(x1) + x2*P(x2) + x3*P(x3) +……+ xn*P(xn)
Example:
Consider an experiment where a fair coin is tossed 3 times and let the number of heads obtained be x. So, the possible values of x are 0,1,2,3. Find the expected value of the experiment.
|
X |
P(x) |
|---|---|
|
0 |
P(0) =1/8 |
|
1 |
P(1) =3/8 |
|
2 |
P(2) =3/8 |
|
3 |
P(3) =1/8 |
Answer:
Expected value E(x) =0*(1/8) + 1*(3/8) + 2*(3/8) + 3*(1/8) = 3/2 or 1.5
Therefore, the expected value for getting a head is 1.5
Types of probability distribution:
There are various methods to represent a random variable like binomial probability distribution, uniform probability distribution, normal probability distribution etc.
How to select the best probability distribution method among them?
One should select a probability distribution method depending on the whether the random variable is continuous or discrete.
Probability distribution methods for representing a discrete random variable:
1. Binomial probability distribution:
- In a binomial distribution, there are n trials.
- Each trial has only two possible outcomes, either success or failure.
- The outcome of a binomial probability distribution gives the probability of success from the n trails.
Formula, BP(X=x) = nCr (p)r (1-p)n-r
Where, BP binomial probability
n total number of trails
p probability of success of an individual trail
r number of successful trials from the total trails
|
X |
BP(X=x) |
|---|---|
|
0 |
P( X=0) = nC0 (p)0 (1-p)n-0 |
|
1 |
P( X=1) = nC1 (p)1 (1-p)n-1 |
|
. |
. |
|
. |
. |
|
N |
P( X=n) = nCr (p)r (1-p)n-r |
Example:
Consider an event where a coin is tossed 3 times. Find the probability of getting exactly 2 heads using binomial probability.
Answer:
given, n =3
p =½ (either heads or tails)
r =2
We know that,
BP(X=x) = nCr (p)r (1-p)n-r
BP(X=2) =3C2 * (1/2)2 * (1-(1/2))3-2 = 3 * (1/4) * (1/2) = 0.375
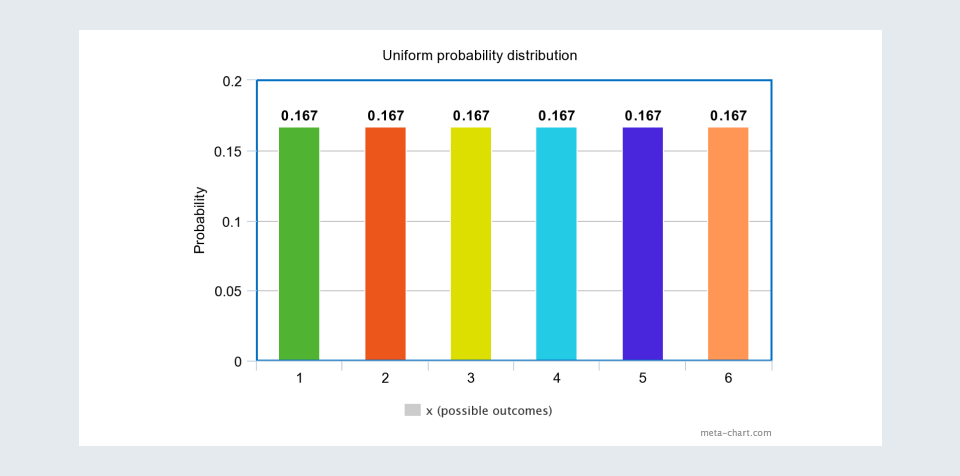
2. Uniform probability distribution:
- Uniform probability distribution method of representing data, is used when the probability of every possible value in random variable is same.
- Consider dice are rolled. The probability of individual possible trial is same for all.
|
X |
P(x) |
|---|---|
|
1 |
1/6 |
|
2 |
1/6 |
|
3 |
1/6 |
|
4 |
1/6 |
|
5 |
1/6 |
|
6 |
1/6 |
Cumulative probability distribution:
- In the above binomial and uniform probability distribution, we represented discrete data but for a single possible outcome, like P(x=2).
- Consider a dice is rolled, what is the probability of getting a number less than 4, I.e. P(x <4). How do we represent it?
- Here we make use of cumulative probability distribution.
- The answer is P(x <4) or P(x<=3) = P(x=0) + P(x=1) + P(x=2) + P(x=3)
|
X |
P(X=x) |
|---|---|
|
0 |
1/2 |
|
1 |
1/6 |
|
2 |
1/6 |
|
3 |
1/6 |
Cumulative probability distribution:
|
X |
P(X <=x) |
|---|---|
|
0 |
0.5 |
|
1 |
0.167 |
|
2 |
0.167 |
|
3 |
0.167 |
Probability distribution methods for representing a continuous random variable:
1. Normal probability distribution:
- Normal probability distribution is widely used for representing continuous random variables.
- The Y-axis in the normal distribution represents the density of probability.
- The X-axis is the probability that a number chosen at random will fall between the two points. Here, mean and standard deviation are used for determining the bell curve or normal distribution curve.
- A normal distribution curve is also known as a bell curve, which is obtained by,
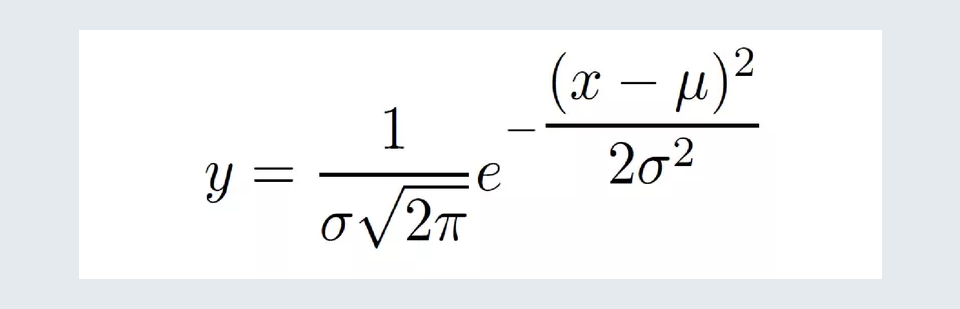
X random variable
μ mean of the population
σ standard deviation of the population
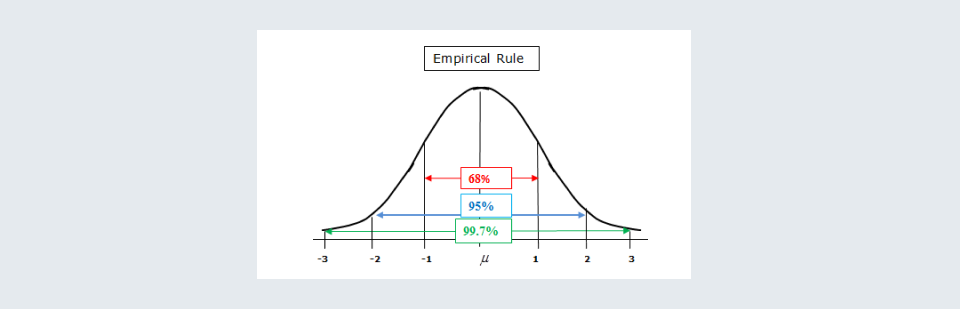
2. Rules for normal distribution curve:
Consider there are a total of 100 values, then according to bell curve:
- About 68 out of 100 values lie within the 1st standard deviation of the mean.
- About 95 out of 100 values lie within the 2nd standard deviation of the mean.
- About 99.7 out of 100 values lie within the 3rd standard deviation of the mean.
Properties of bell curve:
- Mean is always at the center of the curve.
- A bell curve is always symmetric
- Mean = Median = Mode
- Total area under the curve is always 1
Important formulas:
|
For population |
Formula |
|---|---|
|
Population size (N) |
Total no of elements present in the population |
|
Population mean (μ) |
∑_1^N Xi /N where, i=1, 2,….N |
|
Population variance (σ2) |
(∑_1^N Xi - μ)2 /N where, i=1, 2,…N |
|
For sample |
Formula |
|---|---|
|
Sample size (n) |
Total no of elements present in the sample taken |
|
Sample mean ( x̅ ) |
∑_1^n Xi /n |
|
Sample variance (S2) |
(∑_1^n Xi - x̅)2 /n |
Note:
- In any regression model, even if the dependent variable and independent variables are not normally distributed, it does not affect the linear model.
- But the residual errors obtained must be normally distributed. If not, then our considered model is not good for prediction, we must look for another model that well describes our problem.
Central limit theorem:
- The central limit theorem gives us a hypothesis that the mean of sample data will be similar to the mean of actual data (large data), i.e. sample mean(μx) = population mean (μ).
- It is said that mean of sample data is similar to the mean of actual data, but not exactly equal. It means there is a deviation between the means of sample data and actual data.
- This deviation is known as sampling distribution’s standard deviation or standard error.
- Standard error is calculated by,
SE = σ /√n,
SE standard error
σ Population standard deviation
n sample size of sample data
- The sample size we consider should be >=30, so our sampling distribution becomes normally distributed.
- Greater the sample size, accurate the predictions will be.
- If the sample size we consider is less then, standard deviation between the sample mean and the actual mean increases.
Inferential statistics assumes the predictions of sample data to the actual population, to hold this assumption the sample data must represent the actual population data. Now according to the given data, we must know whether to consider a discrete random variable or a continuous random variable. Select an appropriate probability distribution method to represent your data. Consider the hypothesis using central limit theorem (CLT). Checking whether the hypothesis we considered before is valid or not is done in the next phase called hypothesis testing.
References:
- https://www.meta-chart.com/bar
- http://onlinestatbook.com/2/calculators/normal_dist.html
- https://towardsdatascience.com/inferential-statistics-for-data-science-b0075670fc8a
- https://www.analyticsvidhya.com/blog/2017/02/basic-probability-data-science-with-examples/
- https://www.intmath.com/counting-probability/14-normal-probability-distribution.php
- https://stattrek.com/probability-distributions/binomial.aspx
