

Understanding the need for NLP to deal with unstructured data. Learn NLP from scratch and build a small project on it. This blog gives you an overview of the general approach to deal with NLP problems.
Everyone of us uses computer almost on a day-to-day basis. We use it for many things – for making engaging PowerPoint Presentations, checking out emails, using spreadsheets, etc. One such use is Data Analytics. We have been using computers for deriving actionable business insights using data. However, the important point to note here is that most of the data is typically in structured format i.e. data is in form of some numbers, tables, etc. Computers can easily understand such ‘structured’ data and can provide valuable analysis out of it. But, as you might notice, most of the ‘data’ in the world is in ‘unstructured’ format. Finding it difficult to understand what that means – let me explain!
What is unstructured data?
Unstructured data, in simple language, is data that cannot be expressed using rows and columns of a spreadsheet. Examples of unstructured data includes text in form of blogs, social media platforms, website content, emails, voice recordings, etc. You might ask – why to analyze such unstructured data? What can we deriver out of it? As it turns out, there is a lot of information available in unstructured data.
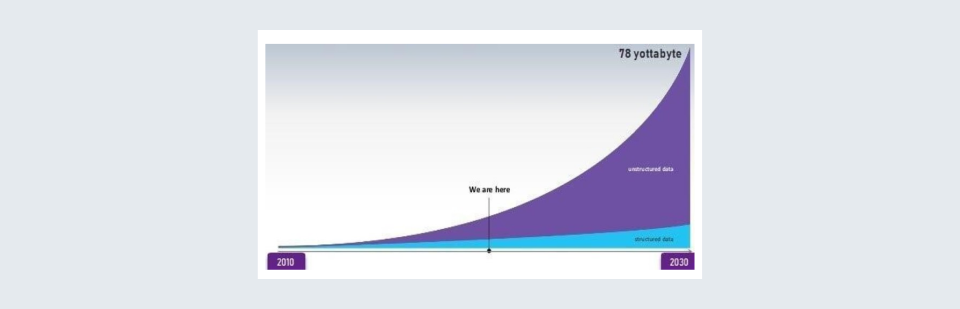
Rising trend in the volume of unstructured data | Source : Guru99
One example – a company has launched a new product and wants to know what customers are thinking. The traditional way of doing the same is using feedback forms/surveys. However, in case of such forms/surveys, sample size is limited. Let us look at other options. With rise in digitization, customers of the product are most probably ‘talking’ about the product on the web. For example, customers might be writing product reviews on e-commerce websites or may be writing an entire blog about it. Now, going through such huge amount of data manually can be daunting and is almost impossible. And here is what we call ‘Natural Language Processing’ will help!
What is Natural Language Processing?
Natural Language Processing or NLP is the approach that is used to understand and analyze textual data. It is a subpart of Artificial Intelligence. To explain it in layman terms, with the help of NLP, machines can also ‘directly’ understand what humans write in text format. Hence the name – Natural Language Processing!
For example, let’s continue with our previous example of a company launching a new product. Using NLP, machines can ‘read’ a customer review on an e-commerce website and classify it as a positive or negative review. Further, with advanced NLP, machine can understand which features are most important for customers.
Applications of NLP
“Ok, Google!”, “Hey Alexa, play my playlist!”, “Siri, set an alarm for 7 O’clock!”. We all know this. All this works on Natural Language Processing. Other examples are Google Translate which let’s which translates text from one language to another using NLP. Chatbots, which use NLP, are also wildly becoming popular.
Businesses are also increasingly relying on NLP for valuable ‘data-driven’ insights. ‘Sentiment Analysis’ is one such popular technique which captures sentiment of customers about a product, brand, service, etc. by analyzing text data available on social media, blogs, and other websites. Companies are using NLP for ‘Market Intelligence’ – understanding best practices and future trends in a market.
NLP algorithms ‘learn’ as more and more data becomes available. Thus, as more unstructured data is becoming available, accuracy of NLP will increase & NLP will continue to grow more powerful in the coming years.
Let us now understand how NLP works -
A General Approach to NLP
To understand a step-by-step approach of dealing with textual data with the help of NLP, let’s consider a following paragraph of text:
“Assume Jack writes blogs and on his platform, he has given his audience an option to review his blogs. He gets around 100–200 reviews a day on his popular blogs. One day he decides to judge how many people are happy with his thoughts on the blogs and how many dislike it. He tries to open the review section and manually judges the response of his readers. He stays there for sometime before exhausting his mind after reading some of the reviews. He gives up the manual approach and hires a firm to give him the overall liking percentage and also asks to build some infrastructure so that the incoming new reviews will also be classified into positive or negative reviews.”
Our objective here to apply NLP on the above text and extract valuable information out of it using Sentiment Analysis. Now, there are 7 steps to do the same:
STEP 1: Collection of Reviews
This is done by using an API to the website and ‘scrapping’ all the reviews. In another world, had there been no API, we would have built a web-crawler for scrapping.
STEP 2: Preprocessing of Data
a) Lowercase: All the reviews on Jack’s blog are not constant in terms of the case. Thus. all the reviews are converted into lowercase.
b) Removal of punctuation, URLs: Punctuation does not add any meaning to the analyses, thus, needs to be removed. URLs also not needed for performing sentiment analysis, thus are removed from the reviews.
c) Removal of ‘stop-words’: There are words that are used a lot by humans, and they are not useful from the point of performing any Sentiment Analysis. Some of the stop words are:

d) Stemming: Humans use different forms of the same word for grammatical reasons. However, all those words still have the same meaning. Thus, stemming helps in breaking all different forms of words to a single form. For example, ‘imagining’, ‘imagination’ ‘imagined’, ‘imagine’ can all be stemmed to ‘imagine’
e) Tokenizing Sentences: Splitting reviews into separate sentence tokens. A single review can have long paragraphs thus are needed to be broken down. If it was a news website, we would filter out POS(Parts-of-Speech) by keeping just the proper nouns as they are most important in this context.
STEP 3: Annotate Corpus
This is the step in which words are either classified as positive or negative. Word frequency tables are also created in this step.
NOTE: ‘NLTK’ package provides this corpus.
STEP 4: Splitting the data into training and testing sets
This helps in creating an unbiased environment and also helps in measuring the accuracy of different models.
STEP 5: Building model(s)
Till now around 70% of the work has been completed. Now, the classification model(s) are built on the training data.
STEP 6: Testing model(s)
Now, the test set data is used on the different models built. Confusion Matrix is used to judge all the results of the models.
STEP 7: Model Selection and pipelining the procedure.
Once, a classification model has been selected. All the reviews are run on the model and the firm tells Jack about the percentage of people liking and disliking his blog!
The above mention are the broad steps that are usually adopted.
Some Hands-On with NLP along with Logistic Regression.
Now, before applying logistic regression to an NLP problem let’s understand what is a ‘word frequency table’.
Based on the annotated corpus, a word frequency table is created which counts the occurrence of specific words in a positive and negative context.
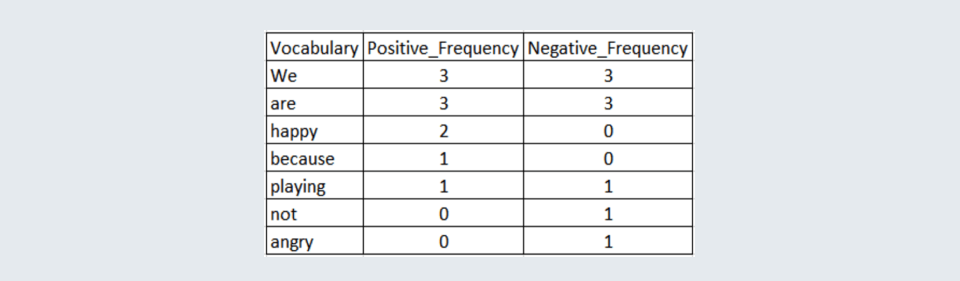
The above is a corpus with the frequency calculation of words used in a positive and negative context.
Now, let’s get down and build a small project to classify sentences as positive or negative.
We will use the NLTK library and for data, the twitter_sample included in the library.
A) Loading the necessary libraries in Python
import nltk
from nltk.corpus import twitter_samples
import matplotlib.pyplot as plt
import random B) Saving positive and negative tweets
nltk.download('twitter_samples')
all_positive_tweets = twitter_samples.strings('positive_tweets.json')
all_negative_tweets = twitter_samples.strings('negative_tweets.json')C) Preprocessing the raw-text, downloading the define ‘stop-words’ data
nltk.download('stopwords')
import re
import string
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
from nltk.tokenize import TweetTokenizerD) Removing URLs and hashtags
# remove old style retweet text "RT"
tweet2 = re.sub(r'^RT[\s]+', '', tweet)
# remove hyperlinks
tweet2 = re.sub(r'https?:\/\/.*[\r\n]*', '', tweet2)
# remove hashtags
# only removing the hash # sign from the word
tweet2 = re.sub(r'#', '', tweet2) E) Tokenizing the tweets: Tweets will get broken into individual words
# instantiate tokenizer class
tokenizer = TweetTokenizer(preserve_case=False, strip_handles=True,reduce_len=True)
# tokenize tweets
tweet_tokens = tokenizer.tokenize(tweet2)F) Removing stop words and punctuations: All stops words mentioned above will be removed along with the punctuations. Stemming of tweets: Root word will be used to all the other forms of that word.
stopwords_english = stopwords.words('english')
tweets_clean = []
for word in tweet_tokens:
if (word not in stopwords_english and
word not in string.punctuation):
tweets_clean.append(word)Now, preprocessing is done!
NOTE: Using utils() library a function process_tweet() can be used for all of the above steps.
Splitting the data into train and test sets
train_y = np.append(np.ones((len(train_pos), 1)), np.zeros((len(train_neg), 1)),axis=0)
test_y = np.append(np.ones((len(test_pos), 1)), np.zeros((len(test_neg), 1)), axis=0)“In statistics, the logistic model (or logit model) is used to model the probability of a certain class or event existing such as pass/fail, win/lose, alive/dead, or healthy/sick.”Source : Wikipedia(hyperlink)
Now on training data, a logistic model is built
def sigmoid(z):
h = 1 / (1 + np.exp(-z))
return h
def gradientDescent(x, y, theta, alpha, num_iters):
m = len(x)
for i in range(0, num_iters):
z = np.dot(x, theta)
h = sigmoid(z)
J = 1.0 / m * (np.dot(np.transpose(y), np.log(h)) + np.dot(np.transpose(1 - y), np.log(1 -h)))
theta -= alpha / float(m) * (np.dot(np.transpose(x), (h - y)))
J = float(J)
return J, theta
Y = train_y
J, theta = gradientDescent(X, Y, np.zeros((3, 1)), 1e-9, 1500)Testing a new tweet on the model built
my_tweet = 'Hi!, I am happy to tell you that I have built my first model using Logistic Regression :)'
[[0.83739526]]
Positive sentimentWell, that’s it. The tweets will now be classified. Now had there been no NLP, this seemed to be impossible!
