

Only 25% of enterprise AI initiatives deliver their expected ROI (IBM, 2025). Not because the technology fails — because the agentic AI architecture does. Organizations throw their most powerful models at every task, burn through budgets on routine operations, and wonder why their agentic AI ROI falls short — and why pilots cost more than the humans they were meant to augment.
Last week, Anthropic published research that stopped us mid-scroll — not because it was new to us, but because it formalized exactly what we’ve been deploying for our clients across our Agentic AI engagements. They call it the Advisor Strategy. We’ve been calling it what it’s always been: the difference between agentic AI that scales and agentic AI that bankrupts.
The $4.4 Trillion Problem Nobody’s Solving Correctly
McKinsey estimates generative AI will unlock 4.4T in annual economic value. IDC projects AI spending will hit 7.84B in 2025 to $52.62B by 2030 — a 46.3% CAGR (Markets and Markets).
And yet:
- 88% of organizations are using AI, but only 6% qualify as “AI high performers” — and those top performers are 3x more likely to have redesigned workflows around AI, not just bolted it on (McKinsey, 2024)
- Gartner projects 33% of enterprise software will include agentic AI by 2028 — but also warns that 40% of agentic AI projects will be canceled by end of 2027 due to escalating costs and governance gaps
- IBM finds 3 out of 4 AI projects fail to meet ROI expectations
The pattern is clear. The gap isn’t in capability — it’s in architectural intelligence. Most organizations deploy agentic AI the same way they deploy interns: hand them the hardest problem and the most expensive tools, then act surprised when costs explode and quality plateaus.
Our Agentic AI practice diagnosed this failure mode early across client engagements. The solution wasn’t more powerful models. It was smarter orchestration.
What Anthropic Actually Announced (And Why It Matters)
On April 9, 2026, Anthropic’s research team — Erik Schluntz and Barry Zhang — published what they call the Advisor Strategy: a tiered model architecture where a cheaper executor model (Haiku or Sonnet) handles routine agent tasks, escalating only complex decisions to a premium model (Opus) acting as an on-demand advisor. The Anthropic advisor pattern has since drawn significant attention across the enterprise AI community — and for good reason.
The results are striking:
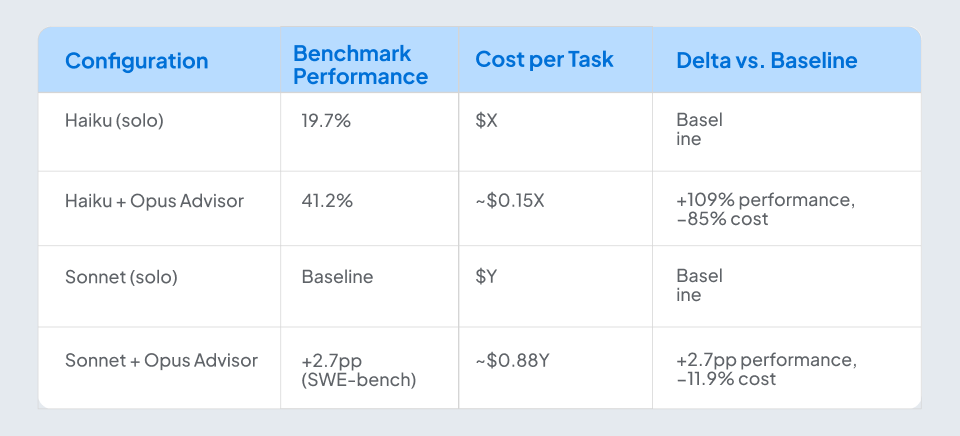
As Anthropic’s researchers put it: “The advisor strategy gives agents an intelligence boost.”
What they didn’t say — what we will — is that this isn’t a new idea. It’s a validated one. Anthropic built the science. We’ve been building the production systems.
The Pattern We’ve Been Deploying: Tiered Intelligence In Agentic AI
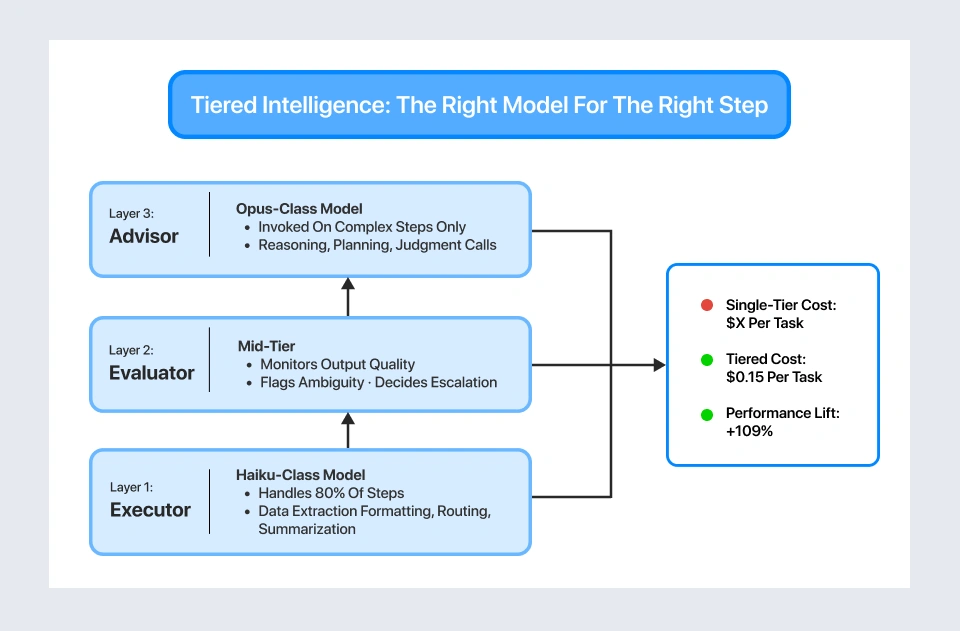
When we began designing agentic AI systems for enterprise clients, we hit the same wall everyone else did: Opus-class models are brilliant but expensive. Haiku-class models are cheap but miss nuance on complex decisions. Running every step of an agent loop through a single model tier is either cost-prohibitive or quality-deficient.
Our answer was a three-layer AI agent orchestration pattern that separates execution from judgment inside every agentic workflow we build. Unlike conventional single-tier setups, this multi-model AI deployment approach routes each agent step to the right model tier based on its complexity and consequence:
- Layer 1: The Executor — lightweight, fast, cheap. Handles the majority of agent steps: data extraction, formatting, routing, summarization, standard tool calls. Runs on models like Haiku. Cost per task: minimal.
- Layer 2: The Evaluator — mid-tier intelligence that monitors executor output quality, flags ambiguity, and decides whether a step needs escalation. This is the layer most implementations miss entirely. Without it, you’re either over-escalating (burning budget) or under-escalating (shipping errors).
- Layer 3: The Advisor — premium intelligence invoked only for high-stakes steps: complex reasoning, multi-step planning, judgment calls with financial or operational consequences. Runs on Opus-class models. Invoked on a small fraction of steps, contributing disproportionate value.
The critical element isn’t the tiers — it’s the escalation logic. We instrument every escalation decision, track outcomes, and tune the Evaluator’s thresholds over the engagement lifecycle. The system learns which task patterns genuinely need premium intelligence and which were false alarms. Cost curves bend downward while quality curves bend upward.
This is exactly what Anthropic’s advisor strategy formalizes at the model interaction level. We’ve been operating at the agent architecture level — where it actually hits production.
Proof: Enterprise Deployments That Already Follow This Pattern
We don’t publish theoretical patterns. Everything below comes from engagements our Agentic AI practice is running right now.
A SaaS Aviation Ticketing Platform — Intelligent Customer Operations
The context: A global airline ticketing platform handling high-volume customer interactions across booking modifications, fare calculations, and disruption management. Their single-tier AI approach couldn’t handle the complexity-cost tradeoff — simple booking queries consumed the same model resources as complex multi-leg rebooking scenarios.
Our agentic architecture:
- Executor: Handles standard booking queries, itinerary lookups, fare displays, and routine modifications — the bulk of interactions
- Evaluator: Detects complex scenarios — irregular operations, multi-carrier rebookings, fare rule edge cases, loyalty program exceptions
- Advisor: Handles rebooking optimization, fare difference reasoning with compliance constraints, and retention decisions requiring judgment
Outcome: Material reduction in per-interaction AI operational cost. Faster resolution on complex disruption scenarios because the advisor layer isn’t throttled by routine queries. Clean separation between cost-sensitive workflows and judgment-sensitive ones.
An Email-to-Jira Automation Agent — Enterprise Workflow Intelligence
The context: A client with high inbound email volume that needed to convert unstructured stakeholder emails into correctly-triaged Jira issues — with the right project, issue type, priority, component tagging, and assignee routing. A single-model approach either missed routing nuance or cost too much at scale.
Our agentic architecture:
- Executor: Parses emails, extracts entities, normalizes fields, drafts the Jira payload
- Evaluator: Scores ambiguity — unclear project routing, conflicting priorities, missing components, sensitive escalations
- Advisor: Invoked only on flagged emails to make routing and prioritization judgment calls, then produces an audit trail for the decision
Outcome: Routine emails are resolved end-to-end at low cost. The advisor is reserved for the emails where getting it wrong matters — reducing triage errors and eliminating the manual cleanup loop the client was absorbing before.
An AI-Powered RFQ Solution — Commercial Intelligence
The same pattern applies at a higher stakes tier for Request for Quotation workflows. The executor handles line-item parsing, catalog matching, and baseline pricing lookups. The evaluator detects non-standard terms, edge-case specifications, and commercial risk indicators. The advisor handles the commercial reasoning — margin calls, alternate sourcing logic, and response drafting for strategic quotes. The more judgment-heavy the workflow, the more valuable tiered escalation becomes.
Is Your Organization Ready? A Tiered Intelligence Readiness Scorecard
Before retrofitting tiered intelligence into your agentic AI deployments, assess where you stand. Score each dimension 1-5 (1 = not started, 5 = mature).
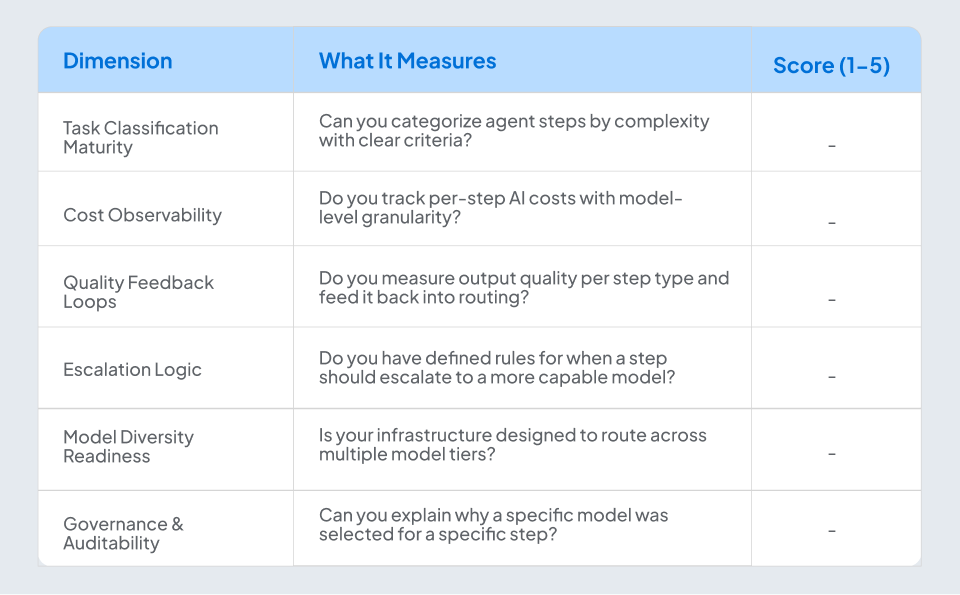
Scoring:
- 24-30: Ready for full tiered intelligence deployment. Let’s accelerate.
- 16-23: Foundation in place. Targeted gaps to close — likely in escalation logic and feedback loops.
- 6-15: Pre-optimization. You’re likely running single-tier agents and leaving 60-80% cost savings on the table.
Research consistently shows that proper enterprise AI cost optimization through tiered intelligence AI yields 60-80% cost reduction for agent operations. The question isn't whether tiered intelligence becomes standard, it's whether you adopt it before or after your competitors do.
The Bottom Line
Anthropic’s advisor strategy isn’t a breakthrough — it’s a benchmark. It confirms, with controlled research, what our production agentic AI engagements have been demonstrating: intelligence should be allocated, not applied uniformly. The organizations that will capture the $4.4 trillion opportunity aren’t the ones running the most powerful models on every step. They’re the ones with the smartest orchestration across their agents.
We’ve been building that orchestration. Now there’s a research paper that agrees with us. Every complex system that works evolved from a simple system that worked — and knew when to call for help. NeenOpal Intelligent Solutions is a GenAI and Data & AI consulting firm and AWS partner. Our Agentic AI practice designs and deploys production-grade agent architectures for enterprise clients across aviation, manufacturing, healthcare, and financial services. Learn more →
Frequently Asked Questions
Q1. Does the advisor pattern only work with Anthropic’s models?
No. The pattern is model-agnostic. We deploy across Anthropic, OpenAI, open-source models, and AWS Bedrock-hosted options. The tiered pattern — cheap executor, intelligent evaluator, premium advisor — works regardless of vendor. Anthropic’s research validates the architecture; it doesn’t lock you into their ecosystem.
Q2. What’s the minimum scale where tiered intelligence makes sense?
Any agentic AI deployment where cost per decision matters. Even at small agent footprints — say, a handful of workflows running business-critical logic — the pattern pays off because the advisor tier is invoked only on the steps where quality mismatch is most expensive. It’s not about volume; it’s about consequence.
Q3. How do you handle latency when a step escalates to the advisor tier?
Escalation adds 2-5 seconds of latency depending on task complexity. For most enterprise use cases — document processing, ticket triage, RFQ generation — this is imperceptible. For real-time customer-facing interactions, we design the evaluator to pre-classify incoming tasks so escalation happens before the user is waiting, not during.
Q4. Isn’t this just “routing” with a fancy name?
Routing is a component. The difference is the feedback loop. Static routing rules degrade as task distributions shift. The pattern we deploy continuously tunes from escalation outcomes — which escalations actually needed premium intelligence, which didn’t, and how thresholds should adapt. It’s the difference between a thermostat and a climate control system.
Q5. What if my team doesn’t have the ML engineering depth to implement this?
That’s precisely what our Agentic AI practice is built for. We design, deploy, and optimize tiered agent architectures as a managed engagement. We handle the evaluator design, escalation logic, cost monitoring, and continuous tuning — your team focuses on business outcomes.
Q6. How long does a typical implementation take?
A production-ready tiered agentic deployment typically takes 8-12 weeks: 2-3 weeks for task taxonomy and baseline measurement, 3-4 weeks for architecture and evaluator development, and 3-5 weeks for deployment, testing, and threshold calibration.
