

Everyone is building AI agents. Very few are shipping ones that survive past the pilot.
The reason isn’t the model. It’s the data underneath it. Unlike chatbots that retrieve information, agents act on it — maintaining state, accumulating memory, and planning multi-step workflows autonomously. That makes the data problem exponentially worse. Agents that can’t access unified, governed, real-time enterprise data don’t just underperform — they automate bad decisions at scale.
This article breaks down why the vast majority of enterprise AI stalls before production, what a production-ready data architecture actually looks like, and how to bridge the gap between prototype and revenue-generating agent.
The “Pilot Trap”: Why Enterprise AI Keeps Stalling
There’s a perception gap killing AI projects from the inside.
Data teams report fragmented sources, inconsistent schemas, and ungoverned pipelines. Executives expect plug-and-play intelligence — point the agent at a dashboard and let it make decisions.
That disconnect is expensive — and the numbers back it up:
• RAND Corporation found that over 80% of AI projects fail, twice the failure rate of non-AI technology projects (RAND, 2024).
• Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data (Gartner, Feb 2025).
• MIT’s “State of AI in Business 2025” report found that 95% of enterprise AI pilots fail to achieve rapid revenue acceleration (MIT/Fortune, Aug 2025).
• McKinsey reports that nearly two-thirds of organizations are still stuck in pilot mode, unable to scale across the enterprise.
As Sasha from Salesforce Ben notes:
"I feel like everyone has very different opinions on whether or not we're actively experiencing a SaaSpocalypse, and I perhaps wouldn't give it as dramatic a name, even though it sticks! I think what we're observing with the SaaS sector and the CRM sector is a wave of change bigger than anything we've seen in at least the last five, maybe even 10 years. AI is as big as the Internet, and it's been disruptive in every sense of the word, so of course the SaaS sector is going to feel that. I think customers continuously want more from their solutions and businesses are scrambling to deliver in a way that benefits them but also gives them something shiny to show stakeholders. Is there likely a bit of panic here? Of course, but that's because the ground is unsteady at the moment. Give these businesses time; I think 2026 will be such a pivotal year for this space as we'll really see who is ahead of the curve and who is kicking their feet madly under the surface." —Sasha, Tech Journalist at Salesforce Ben & NowBen
The root cause: legacy SaaS silos create what we call semantic drift — the same data means different things in different systems. “Revenue” in your CRM is not the same “Revenue” in your ERP. An agent reasoning across both will produce confidently wrong answers.
An agent without unified data doesn’t just fail — it automates failure. It routes the wrong inventory to the wrong warehouse. It approves a discount that violates pricing policy. It escalates a support ticket to a team that was restructured six months ago.
Until the data layer is unified, agents are guessing. And guessing at machine speed is worse than not guessing at all.
Core Pillars of a Production-Ready AI Stack
Getting agents into production requires three foundational layers. Skip any one of them and you’re building on sand. At NeenOpal, we’ve operationalized these three layers across enterprise clients in aviation, healthcare, and manufacturing — each with different data maturity levels. The pattern holds regardless of industry.
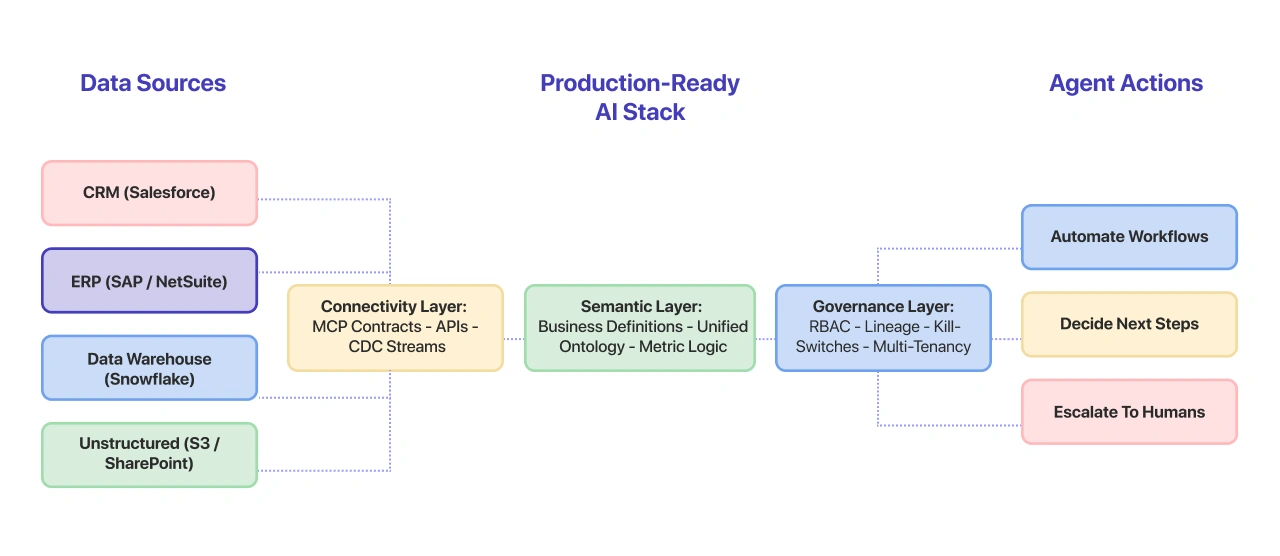
The Connectivity Layer
Enterprise data lives in dozens of systems — CRMs, ERPs, data warehouses, SaaS platforms, unstructured document stores. Agents need a standardized way to access all of it.
This is where the Model Context Protocol (MCP) comes in. MCP provides a universal interface for AI models to connect to external data sources and tools. Instead of building custom integrations for every system, you define MCP contracts that abstract the complexity.
The result: agents can query Salesforce, pull from Snowflake, and read from S3 — all through one consistent protocol.
The Semantic Layer
Raw data isn’t agent-ready data. The semantic layer resolves the gap between how data is stored technically and how the business actually thinks about it.
• “Customer churn” means something specific in your organization — is it 30-day inactivity? Contract non-renewal? Revenue drop below threshold?
• “Pipeline velocity” might be calculated differently across regions.
• “Active user” has a dozen definitions depending on who you ask.
The semantic layer codifies these business definitions so agents operate on the same truth as your teams. Without it, every agent builds its own interpretation — and they’ll all be slightly different. At NeenOpal, we bridge this gap by designing robust data engineering and architecture that standardizes these definitions, ensuring your AI agents act on a single, unified source of truth.
The Governance Layer
Agents operating autonomously need guardrails:
• Security — which data can the agent access? What actions can it take? Role-based access control isn’t optional when AI is making decisions.
• Multi-tenancy — in SaaS environments, agents must be scoped to the right tenant. Cross-tenant data leakage in an agentic system is a compliance nightmare.
• Lineage — every decision an agent makes should be traceable back to the data it used. When something goes wrong, you need an audit trail — not a black box.
Architectural Patterns That Prevent Agents from Failing
Theory is useful. Patterns are actionable. Here are four architectural patterns that separate production agents from expensive demos.
Medallion Architecture
Structure your data pipeline into three tiers:
• Bronze (Raw) — ingest everything as-is. No transformations, no opinions. This is your system of record.
• Silver (Curated) — clean, deduplicate, conform schemas. This is where data becomes comparable across sources.
• Gold (Agent-Ready) — pre-computed feature sets, business metrics, and decision-ready aggregations. This is what agents consume.
Agents should never touch Bronze. If they’re querying raw data, your pipeline has a gap. We’ve also seen teams let agents query Silver when Gold isn’t ready — the result is agents reasoning on half-cleaned data, which is arguably worse than raw. It looks right but isn’t, and that false confidence propagates downstream.
Lakehouse + Vector Storage
Production agents need both:
• Structured data (SQL tables, metrics, transactional records) for quantitative reasoning.
• Unstructured knowledge (documents, policies, Slack threads, support tickets) for contextual reasoning via RAG.
A lakehouse architecture — combining the best of data lakes and warehouses — paired with vector storage for embeddings gives agents the dual capability they need.
Data Mesh for Domains (With a Caveat)
Centralized data teams don’t scale. When you have 15 business domains generating data, a single team can’t maintain quality across all of them.
Data mesh distributes ownership to domain teams. Each domain publishes its data as a product — with defined schemas, SLAs, and quality guarantees. Agents consume these data products through standardized contracts.
The caveat: data mesh assumes domain teams have the engineering maturity to own their data products. In practice, we’ve seen teams ship “data products” that are just renamed database views with no schema versioning, no SLAs, and no monitoring. If your domain teams aren’t ready to operate as data product owners, mesh becomes a governance vacuum — not a solution. Start with 2–3 high-maturity domains and expand only after they’re consistently meeting their contracts.
Real-Time Integration
Batch pipelines that refresh overnight are fine for dashboards. They’re not fine for agents making decisions at 2 PM about inventory that changed at 10 AM.
Change Data Capture (CDC) and event-driven architectures replace batch with real-time streaming. Agents operate on data that’s minutes old, not hours.
If your agent is making decisions on stale data, it’s making stale decisions.
From Chatbots to Agents: Designing for Decision Velocity
Most AI metrics focus on accuracy. That matters, but it misses the point in an agentic context.
The metric that matters for agents is Decision Velocity — how quickly your organization can go from data event to informed action.
Decision Velocity = (Data Freshness × Context Completeness × Governance Confidence) / Time to Action
A high decision velocity means:
• Data arrives in near real-time (freshness).
• The agent has access to all relevant context — structured and unstructured (completeness).
• Governance guardrails are automated, not manual bottlenecks (confidence).
• The action happens in seconds, not days (time).
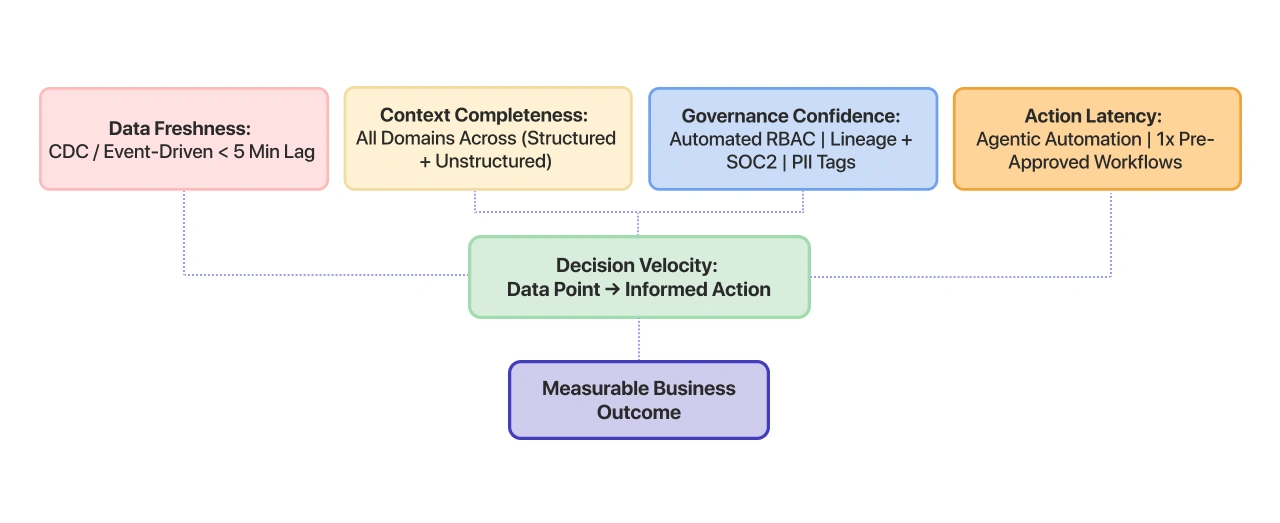
The Decision Velocity Scorecard
CTOs should audit their current stack against these five dimensions:
|
Dimension |
Low Velocity |
High Velocity |
|
Data Freshness |
Nightly batch refreshes |
CDC / event-driven, < 5 min lag |
|
Context Access |
Agents query 1–2 sources |
Agents access all relevant domains via MCP |
|
Semantic Clarity |
Business terms undefined |
Codified semantic layer across domains |
|
Governance |
Manual review for every action |
Automated RBAC + lineage + kill-switches |
|
Action Latency |
Human-in-the-loop for all decisions |
Agent-autonomous for pre-approved workflows |
If you score “Low” on three or more, your agents aren’t ready for production — regardless of how good the model is.
Building the “Connective Glue” for Global SaaS
The hardest part of making agents work isn’t the AI. It’s mapping business meaning across disparate systems so the agent can reason holistically.
Consider a global SaaS platform running Salesforce for CRM, SAP for ERP, and Snowflake for analytics. “Customer” means something different in each system. “Revenue” is calculated differently. “Active” has three definitions.
The solution isn’t ripping out systems. It’s building the connective glue — a translation layer that:
• Maps business terms across CRM, ERP, and analytics platforms into a shared ontology.
• Resolves conflicts (when CRM says revenue is $1.2M and ERP says $1.1M, which is right, and why?).
• Exposes unified views through API and MCP contracts that agents consume.
By implementing these custom AI solutions and agentic frameworks, organizations can move beyond fragmented data silos and empower their agents with the "connective glue" necessary for autonomous, high-velocity decision-making.
What This Looks Like in Practice
A SaaS airline ticketing platform serving 200+ airline clients had built an AI-powered flight booking assistant — an agentic system that needed to reason across three data sources: the CRM for customer profiles, a proprietary booking engine for real-time availability, and a legacy fare management system for pricing rules.
The agent was confidently returning fare quotes that didn’t match actual availability. The booking engine showed seats available; the fare system showed them at one price; the CRM showed the customer eligible for a different tier. The agent had no way to reconcile these three truths.
The fix wasn’t a better model. It was a unified semantic layer that mapped “available fare” into a single definition reconciling real-time inventory, pricing rules, and customer tier — exposed through MCP contracts. The result: the agent went from generating support tickets to resolving bookings autonomously.
This is the work we do at NeenOpal — building the connective tissue between enterprise systems so agents can reason across the full business context, not just one silo at a time.
Operationalizing Safely
Production agents need operational discipline:
• Gradual rollouts — start agents on low-risk, high-frequency tasks. Expand scope only after proving reliability.
• Kill-switches — every agent must have a circuit breaker. If error rates spike, the agent stops and escalates to a human.
• Incident monitoring — track agent decisions the same way you track production deployments. Set alerts on anomalous behavior.
The Readiness Checklist
Before you deploy your first production agent:
1. Inventory critical domains — which data sources must the agent access to do its job?
2. Verify real-time data paths — are those sources available in near real-time, or are you still on batch?
3. Define API/MCP contracts — does every data source have a well-documented, versioned interface?
4. Codify business definitions — is there a semantic layer that resolves ambiguity?
5. Establish governance — are RBAC, lineage, and kill-switches in place?
If the answer to any of these is “no,” you’re not ready. And that’s fine — better to know now than after the agent makes a $100K error.
Conclusion: Agents Are Only as Smart as the Data They Access
The 2026 AI conversation has shifted from “can we build agents?” to “can we trust them?”
Trust doesn’t come from better models. It comes from unified enterprise data, governed access, and real-time connectivity. The organizations that get this right will move from shiny prototypes to agents that drive measurable business outcomes. The rest will keep stacking pilots that never ship.
The foundation isn’t optional. It’s the whole game.
Akshat Agrawal is the Engagement Manager at NeenOpal Intelligent Solutions, an AWS partner specializing in GenAI and Data & AI consulting. NeenOpal helps enterprises build production-ready AI systems — from data architecture to deployed agents.
Featured Contributors
Sasha Semjonova Tech Journalist at Salesforce Ben & NowBen A special round of applause to Sasha for her invaluable perspective on the "2026 Pivotal Shift." Her deep coverage of the SaaS and CRM sectors at Salesforce Ben and NowBen provided the market context for this piece, specifically regarding the "SaaSpocalypse" and why enterprise data unity has become a survival requirement in the age of Agentic AI.
FAQ
What is unified enterprise data?
Unified enterprise data is a single, governed, semantically consistent view of business information drawn from all source systems — CRMs, ERPs, data warehouses, and unstructured stores — accessible through standardized interfaces like MCP contracts. It eliminates the problem of the same metric meaning different things in different systems, giving AI agents a reliable foundation to reason and act on.
Why do AI agents fail in enterprise environments?
Most failures trace back to fragmented, stale, or ungoverned data — not the AI model itself. RAND Corporation found that over 80% of AI projects fail, and Gartner predicts 60% of AI projects will be abandoned through 2026 due to lack of AI-ready data. Agents that can’t access complete, real-time context make confidently wrong decisions — automating errors instead of solving problems.
What is the Model Context Protocol (MCP)?
MCP is a standardized protocol that allows AI models and agents to connect to external data sources and tools through a universal interface, replacing custom point-to-point integrations with consistent contracts. In practice, MCP lets an agent query your CRM, data warehouse, and document store through one consistent interface — without building separate connectors for each system. This dramatically reduces integration overhead and makes agents portable across enterprise environments.
What is Decision Velocity?
Decision Velocity measures how quickly an organization can go from a data event to an informed, automated action. It’s a function of four factors: data freshness, context completeness, governance confidence, and action latency. Organizations with high decision velocity operate on real-time data, give agents access to all relevant domains, automate governance guardrails, and enable agents to act autonomously on pre-approved workflows — reducing the time from event to action from days to seconds.
How do I know if my organization is ready for production AI agents?
Audit your data stack against five dimensions: data freshness (real-time vs. batch), context access (how many sources agents can reach), semantic clarity (are business terms codified), governance automation (RBAC, lineage, kill-switches), and action latency (human-in-the-loop vs. agent-autonomous). If you score low on three or more, focus on the data foundation before scaling agents — the model won’t compensate for missing infrastructure.
Sources
• RAND Corporation — AI Project Failure Rate Analysis
• Gartner — Lack of AI-Ready Data Puts AI Projects at Risk (Feb 2025)
• Gartner — 30% of GenAI Projects Abandoned After POC (Jul 2024)
• MIT / Fortune — 95% of AI Pilots Failing (Aug 2025)
• Pertama Partners — AI Project Failure Statistics 2026
