

There is a deceptively simple equation that has started to reshape how serious AI Harness Engineering teams think about agent deployment:
Agent = Model + Harness.
If you’re not the model, you’re the harness. LangChain’s engineering team defined this in March 2026, and it cuts through a year’s worth of vague “agentic AI” discourse. A raw model is not an agent. It becomes one when a harness gives it a durable state, tool execution, feedback loops, and enforceable constraints. The model contains the intelligence. The harness is the system that makes that intelligence useful.
At NeenOpal, every solution we build for enterprise clients is built as a harness, not just a prompt. This article explains what that means, why it matters, and what enterprise-grade harness engineering actually looks like in practice.
Why the Model Is Not the Problem
The enterprise AI failure pattern is well-documented at this point.
- RAND Corporation found that over 80% of AI projects fail, and the dominant causes are not model quality. They are inadequate observability, undefined failure modes, and the absence of human override mechanisms.
- McKinsey’s 2025 State of AI report found fewer than 25% of enterprise AI deployments operating at scale. The rest stalled in pilot or were quietly decommissioned.
- Gartner predicts that through 2026, organizations will abandon 60% of AI projects due to a lack of AI-ready infrastructure, not models.
The pattern is consistent: the model does what it’s capable of. The harness around it, or the lack of one, determines whether that capability becomes a business asset or a liability.
An agent without a harness is like a skilled contractor let loose in your facility with no brief, no access controls, no logging, and no way to undo their work. They might do something useful. You have no way to know, and no way to course-correct.
What Harness Engineering Actually Means
AI Harness Engineering is the discipline of designing the systems, constraints, and feedback loops that wrap around enterprise AI agents to make them reliable in production. The canonical framework, formalized by Birgitta Böckeler at Thoughtworks and expanded by LangChain’s engineering team, structures the harness around two control types:
Guides (feedforward controls) anticipate agent behavior and steer it before it acts. They increase the probability of correct output on the first attempt. Sensors (feedback controls) observe after the agent acts and enable self-correction. Particularly powerful when optimized for LLM consumption, custom error messages that include instructions for self-correction are a form of positive prompt injection.
Without guides, agents repeat the same mistakes because there’s nothing steering them away from known failure modes. Without sensors, agents encode rules but never find out whether they worked. Both are required.
Each control is also either:
- Computational: Deterministic, fast, CPU-executed. Tests, linters, type checkers, schema validators. Run in milliseconds; results are reliable.
- Inferential: Semantic, AI-executed. LLM-as-judge review, reasoning checks, policy classification. Slower and non-deterministic, but capable of evaluating outputs no rule-based system can catch.
This 2x2 framework covering Guides vs. Sensors and Computational vs. Inferential is the foundation of a production harness and a core Agentic Design Pattern. The question at every design decision is: which quadrant does this belong in, and have we covered all four?
The Six Core Components Every Enterprise Harness Needs

1. Durable State and Filesystem Primitives:
A model’s native scope is its context window. When the session ends, it’s gone. That’s not how enterprise workflows operate. Production agents need a durable state, a workspace where work can be incrementally built, intermediate outputs stored, and context preserved across sessions. The filesystem is the foundational harness primitive because of what it unlocks:
- Agents read real data: documents, schemas, policy files, customer records
- Work survives context window limits via structured offloading
- Multiple agents and humans can coordinate through a shared state, a critical requirement in multi-agent Agentic Workflow Infrastructure
For enterprise deployments, this means explicit design decisions about what data the agent persists, in what format, with what retention and access policy. These are not model decisions. They are the harness decisions.
2. Sandboxed Execution Environments:
Agents that can only reason cannot complete work. Agents that can act without constraint are a risk surface. Sandboxes give agents safe operating environments: isolated, scoped, auditable execution where they can run code, call APIs, install dependencies, and interact with external systems without exposing production infrastructure to uncontrolled agent behavior.
For enterprise business agents handling customer support, operational workflows, and financial processing, the sandbox boundary defines what the agent can and cannot touch. Harness engineers decide what tools are available, what APIs are exposed, what actions require human approval, and what the agent cannot do by design rather than by instruction. The key distinction: instructions are suggestions. Sandbox boundaries are constraints.
3. Memory Architecture:
Context rot is the silent killer of long-running agents. As conversation history and tool outputs accumulate in the context window, model performance degrades. The agent becomes less coherent, drops earlier constraints, and starts reasoning on noise rather than signal.
A production harness manages memory explicitly across tiers:

Compaction strategies handle context window saturation, intelligently summarizing and offloading earlier context so the agent can continue working without starting over. Tool call offloading manages large API responses that would otherwise flood the context with low-signal data.
Each of these is a harness-level design decision. Without explicit memory architecture, agents either lose critical context mid-task or accumulate stale information that corrupts current reasoning.
4. The Guardrail System:
Prompt-based guardrails fail. Not sometimes, but systematically, under adversarial inputs, extended context, and subtle prompt injection. The longer the system prompt, the more likely earlier constraints conflict with newer additions. The agent finds the gap.
Production guardrails operate at the infrastructure level across three enforcement points:
- Input Validation: Classify and sanitize all inputs before they reach the model. Off-topic requests, policy violations, and potential injections are caught before the LLM processes them.
- Output Validation: Parse every agent output against expected schemas. Malformed responses are rejected or rerouted before reaching downstream systems.
- Action Validation: For consequential actions such as database writes, financial transactions, and external API calls, validate the intended action against a policy engine before execution. The agent proposes; the policy engine approves or blocks.
These Autonomous Agent Guardrails form the enforcement backbone of any enterprise-grade harness. OpenAI’s engineering team documented their own harness approach: layered architecture enforced by custom linters and structural tests, with recurring “garbage collection” that scans for drift and has agents suggest fixes.
Their conclusion: “Our most difficult challenges now center on designing environments, feedback loops, and control systems.” This is an AI lab building coding agents, admitting that the model is not the hard part.
5. Observability and Trace Attribution
You cannot trust what you cannot see. A complete observability stack for production agents covers:
- Full Trace Logging: Every reasoning step, tool call, input, output, and timing recorded per task.
- Decision Attribution: For each output, which memory retrievals and tool outputs contributed to it.
- Error Taxonomy: Structured classification of failures: model errors, tool failures, guardrail triggers, timeout events.
- Behavioral Drift Detection: Automated comparison of current behavior against baseline. If the agent starts behaving differently without a deployment, that’s a signal worth catching before a user does.
In regulated industries such as healthcare, aviation, and financial services, observability is not an engineering nicety. It is the audit trail that makes agentic AI legally defensible. Every decision the agent makes must be traceable back to the data it used and the logic it followed.
6. The Evaluation Harness
A deployed agent is software. Software regresses. Without continuous evaluation, you will not know when it does. The evaluation harness runs automated tests on every deployment:
- Golden Set Evaluation: Fixed input/output pairs where correct behavior is known. Drift is caught at deploy time.
- Behavioral Contract Testing: Verify guardrail compliance under adversarial and edge-case inputs.
- Latency Regression Testing: Quality cannot come at the cost of response time in production environments where SLAs exist.
- Tool Contract Validation: External APIs change. Automated checks catch schema drift before it propagates into agent behavior.
The evaluation harness is the feedback sensor applied to the entire system, not individual interactions. It catches systemic regressions that interaction-level logging misses.
The Three Harness Dimensions
Böckeler’s framework at Thoughtworks categorizes what a harness is trying to regulate into three dimensions. The enterprise application of each is worth making explicit:
- Maintainability Harness: Structural quality controls: static analysis, linting, schema validation, dependency monitoring. These are computational sensors that run cheaply on every change. In enterprise AI, this translates to API contract validation, data schema conformance checking, and integration health monitoring.
- Architecture Fitness Harness: Controls that define and enforce the characteristics of the system: performance requirements, observability standards, reliability SLOs. For enterprise AI agents, this includes response latency guardrails, memory retrieval accuracy thresholds, and integration availability requirements.
- Behaviour Harness: Functional correctness: does the agent actually do what it’s supposed to do? This is the hardest dimension and the most critical. It requires a combination of golden set evaluation, human-in-the-loop review processes, and inferential sensors (LLM-as-judge) for semantic quality assessment. Computational sensors alone cannot evaluate whether an agent gave a correct customer resolution or an accurate financial recommendation.
Most enterprise AI deployments today have weak behaviour harnesses. They rely on post-hoc human review rather than structured evaluation. This is the primary reason pilots don’t scale, as scaling a behaviour harness requires investment most teams make after they’ve discovered the need, not before.
Harness Templates: The Enterprise Scaling Pattern
Mature engineering organizations codify common service topologies into templates. The same principle applies to Agentic Workflow Infrastructure. Harness templates are bundles of guides and sensors pre-configured for a specific agent topology, such as a customer support agent, a document processing agent, or an operational workflow agent. They encode:
- The tool registry with permitted actions and permission scopes
- Pre-built evaluation suites for the domain
- Memory architecture configured for the task type
- Autonomous Agent Guardrails aligned to industry requirements (HIPAA, SOC2, GDPR)
At NeenOpal, we maintain harness templates for the agent topologies we deploy most frequently: support resolution agents, data extraction agents, operations automation agents, and multi-agent orchestration systems. New client deployments start from a template, not a blank canvas. The template provides the harness structure; client-specific configuration provides the business context.
This is how enterprise AI scales without sacrificing reliability. You are not rebuilding the harness from scratch for every engagement. You are instantiating a proven Agentic Design Pattern and configuring it to the client’s context.
What “Vibe Engineering” Actually Costs
There is a category of agentic AI work we have started calling vibe engineering, systems held together by increasingly complex prompts, undocumented tool integrations, and tribal knowledge about which edge cases to avoid.
Vibe-engineered agents work in demos. In production, they fail predictably:
- Prompt Drift: As the system prompt grows, earlier constraints conflict with newer additions. The agent finds the gap.
- Context Window Pressure: As sessions extend, early constraints drop out of context. The agent loses its behavioral anchors precisely when it needs them most.
- Tool Contract Drift: External APIs update their schemas. Without versioned tool contracts, the agent silently starts consuming malformed data.
- Invisible Regressions: A model update from the provider changes subtle behavior. Without an evaluation harness, nobody notices until a user escalates.
Retrofitting a production harness onto an existing vibe-engineered agent typically takes 4–8 weeks, significantly more than building it correctly from the start. The earlier harness architecture enters the development lifecycle, the lower the total cost of the deployment.
The Harness Readiness Scorecard
Before deploying any agentic system to production, we assess against six dimensions:
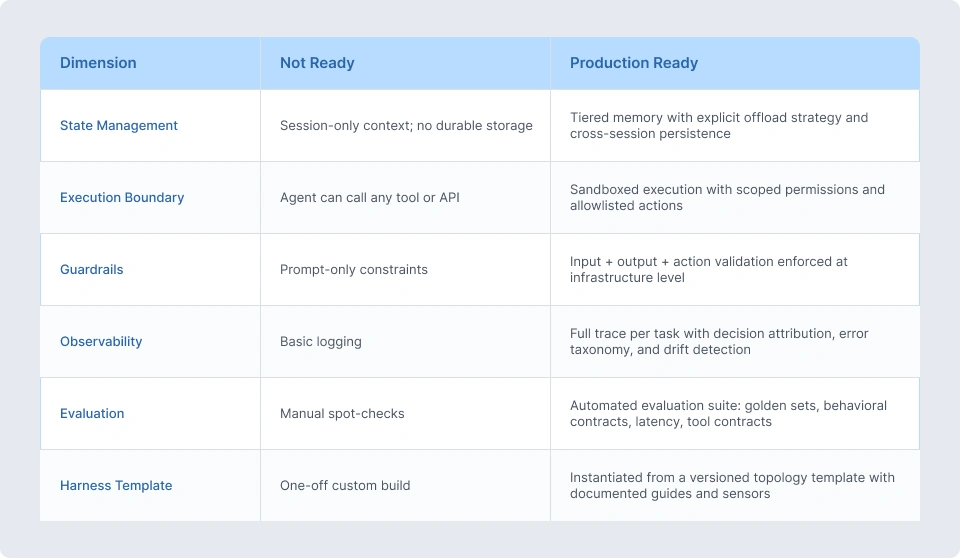
Three or more “Not Ready” scores means the system is not production-ready regardless of model quality. Deploying early does not accelerate; it creates technical debt that compounds with every production interaction.
What This Means for Your AI Strategy
The 2026 enterprise AI challenge has shifted from “can we build agents” to “can we trust them at scale.”
Trust is not a model property. It is a harness property. It comes from guides that steer enterprise AI agents toward correct behavior before they act, sensors that catch deviation before it reaches users, memory systems that keep context accurate, sandboxes that bound what agents can touch, and evaluation loops that catch regressions before they become incidents.
The organizations investing in AI Harness Engineering now are building agents that scale. The ones running on vibe engineering are building technical debt that scales instead.
The equation is simple: Agent = Model + Harness. The model is largely solved. The harness is the work.
Frequently Asked Questions
Q1. What is the canonical definition of a harness in AI agent systems?
The canonical definition, established by LangChain’s engineering team in 2026: Agent = Model + Harness. If you’re not the model, you’re the harness. A harness is every piece of code, configuration, and execution logic that isn’t the model itself, covering durable state, tool execution, guardrails, memory management, observability, and evaluation loops. The model contains intelligence; the harness makes that intelligence useful.
Q2. What are guides and sensors in harness engineering?
Guides are feedforward controls that steer agent behavior before it acts, increasing the probability of correct output on the first attempt. Sensors are feedback controls that observe after the agent acts, enabling self-correction. Both are further classified as computational (deterministic, fast, rule-based) or inferential (AI-executed, semantic). A complete harness requires all four: computational guides, inferential guides, computational sensors, and inferential sensors. Together, they form the foundation of effective Agentic Design Patterns.
Q3. Why do prompt-based guardrails fail in production?
As system prompts grow, earlier constraints conflict with newer additions and the model finds the gap. Under adversarial inputs or extended context, prompt constraints degrade. Prompt-based guardrails also cannot enforce action boundaries; they can ask an agent not to write to a database, but infrastructure-level Autonomous Agent Guardrails can ensure it structurally cannot. Production guardrails operate at the infrastructure level: input validation, output schema enforcement, and action policy checks before execution.
Q4. What is context rot and how do harnesses address it?
Context rot is the degradation of model performance as the context window fills over a long session. Agents become less coherent, drop earlier constraints, and reason on accumulated noise. Harnesses address context rot through compaction (intelligent summarization and offloading of earlier context), tool call output management (keeping head/tail tokens while offloading full outputs to storage), and tiered memory architectures that separate what lives in-context from what is retrieved on demand.
Q5. What is a harness template?
A harness template is a versioned, pre-configured bundle of guides and sensors for a specific agent topology, for example, a customer support agent, a document processing agent, or an operational workflow agent. Templates encode the tool registry, evaluation suites, memory configuration, and Autonomous Agent Guardrails appropriate to the topology. Enterprise teams instantiate templates for new deployments rather than rebuilding harness architecture from scratch, ensuring consistency and reducing time-to-production.
Q5. How does NeenOpal implement harness engineering for enterprise clients?
NeenOpal builds all agentic solutions against a reference AI Harness Engineering architecture using AWS Bedrock for model inference, OpenSearch for vector retrieval, DynamoDB for episodic memory, and Lambda for orchestration. Every deployment includes sandboxed execution environments with scoped tool permissions, tiered memory systems with explicit context management, infrastructure-level Autonomous Agent Guardrails at input/output/action boundaries, full trace observability with decision attribution, and automated evaluation suites running on every deployment.
New engagements are instantiated from harness templates matched to the deployment topology, building on proven Agentic Workflow Infrastructure from day one.
