

Overview
Our client, a prominent entertainment company, faced persistent delays and quality issues caused by incomplete metadata within critical content systems. Manual efforts to validate and enrich records created bottlenecks and limited scalability. We built an autonomous data enrichment solution using agentic AI that detects missing fields, extracts reliable information from trusted sources, and updates databases with validated, confidence-scored insights.
70%
Reduction in manual enrichment time overall
40%
Improvement in Metadata Completeness within weeks
90%
Automated Processing Accuracy on validated fields
Customer Challenges
The client faced inconsistent, fragmented metadata that slowed operations. Manual teams spent too much time searching for missing details across multiple sources, often without knowing which data was reliable. This led to delays, lower throughput, and frequent errors.

Metadata Quality Gaps
Key content attributes were frequently missing or outdated, requiring extensive effort to search, validate, and update information. These repeated manual steps reduced throughput and made the content pipeline prone to error, inconsistency, and operational delays.

High Manual Effort
Teams spent significant time gathering metadata from scattered sources. The repeated effort drained productivity and made scaling the process difficult.

Lack of Data Reliability Indicators
With no clear markers showing which metadata source was trustworthy, teams struggled to confirm accuracy, leading to rework, slower decision-making, and operational bottlenecks.
Agentic AI Architecture for Automated Metadata Enrichment
Agentic AI integrates with content systems to identify metadata gaps, validate sources, and automate enrichment at scale.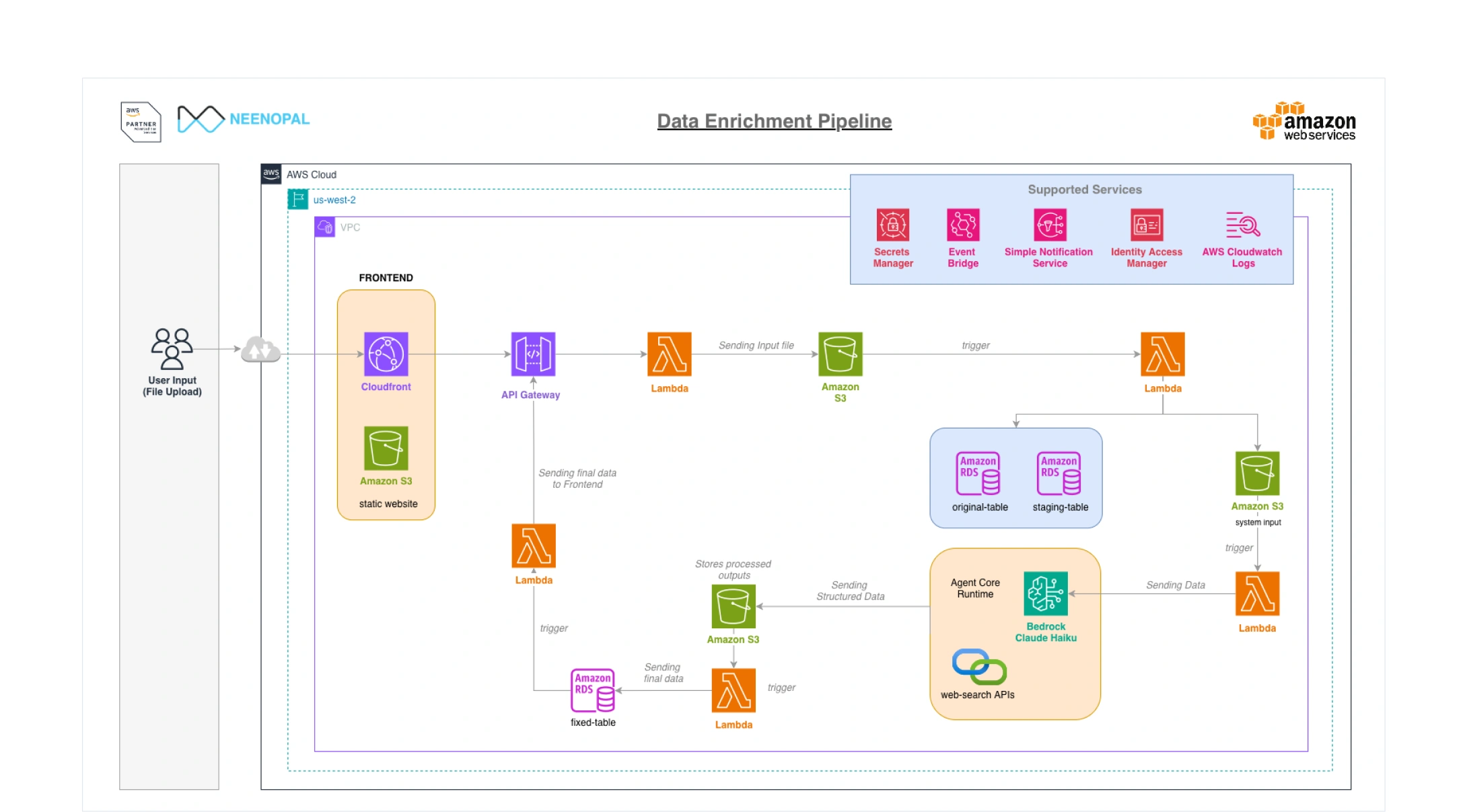
Solutions
We built an autonomous enrichment workflow using agentic AI that plugs directly into the client's pipeline. It detects missing fields, fetches trusted data through external connectors, scores source credibility, and writes enriched metadata back with confidence scores, removing manual work and ensuring consistent, high-quality metadata at scale.
01.
Autonomous Metadata Enrichment Agent
The solution uses AWS Bedrock, AgentCore, AWS Lambda, and event-driven triggers. It applies a custom confidence score combining model outputs with source authority. External APIs like SerpAPI provide verified public data, enabling fully automated, accurate enrichment within existing pipelines.
02.
Automated Source Credibility Checks
Each retrieved value is evaluated across multiple signals, including model certainty, cross-source agreement, and domain authority, ensuring only high-trust metadata enters the client's systems.
03.
Seamless Pipeline Integration
The workflow attaches to existing ingestion and QC steps with minimal changes, supporting large-scale content operations without disrupting legacy processes or adding overhead.
Unlock Scalable, Confidence-Scored Metadata Enrichment for Enterprise Content Pipelines
Explore the SolutionServices




Benefits

Automated Metadata Enrichment Workflow
The client achieved faster content readiness and higher metadata accuracy, while automation improved consistency and reduced costs overall.

Improved Content Discovery & Searchability
With cleaner, complete metadata, titles became easier to categorize and surface across platforms, enhancing recommendations, search relevance, and overall user experience.
Scalable Operations With Reduced Load
Automation removed repetitive tasks, reduced dependency on manual QC, and allowed the pipeline to scale to higher content volumes without increasing operational effort.
Conclusion
The autonomous enrichment engine delivered a scalable, production-ready solution that improved metadata quality, reduced operational friction, and unlocked faster time-to-value. By combining agentic AI with robust validation, the client now runs a more reliable and efficient content pipeline built for future growth.
FAQ
Autonomous Metadata Enrichment with Agentic AI – Frequently Asked Questions
Which AWS services power this solution?
The enrichment workflow is built using AWS Bedrock, Amazon Bedrock AgentCore, AWS Lambda, and Amazon S3, enabling scalable, event-driven processing. These services work together to orchestrate AI reasoning, execute enrichment tasks, store metadata, and integrate seamlessly into existing pipelines.
Can this solution integrate with existing content pipelines?
Yes. The agentic enrichment engine is designed to plug into existing ingestion and quality control workflows with minimal disruption. It operates as an intelligent layer within the pipeline, ensuring compatibility with legacy systems while enhancing automation and scalability.
How quickly can organizations see measurable impact?
In this case, the client achieved a 70% reduction in manual enrichment time and a 40% improvement in metadata completeness within weeks. Since the solution is event-driven and modular, organizations can begin seeing improvements soon after deployment.
Authors



Contact Us
We’d love to hear from you.
Lets discuss how we can transform your business with AI. Talk to our AI expert team. Lets do AI journey together.