

In this blog, we are going to talk about our work in Recommendation Engines with a top cosmetic brand of one of the largest CPG companies in the world. As the name suggests, recommendation engines are algorithms that study the past data and make relevant suggestions for a user. But as with any real-life situation, there is a catch. We do not have user data. In this blog, we will explain to you in detail about the Recommendation Engine – what it is, how it works, what are its benefits and how we customised it. Let us start!
Why Recommendations Are Important?
Let us discuss a scenario – suppose you are shopping on an e-commerce mobile application, looking for a gift for your mother for her birthday. You search using filters & search bar and explore various options available. The e-commerce platform also shows you ‘recommend for you’ products based on your past searches, past orders, mobile application interaction behaviour, etc. Just imagine – if you actually end up liking and buying the recommended product, you feel satisfied since you could find a good fit with less effort.
Now consider a second scenario – you are shopping on an e-commerce website – this time for yourself. You like something and you add it to the cart. While checking out, the website shows you ‘you may also like’ recommendations. Many times, you may end up adding those products to your cart as well.
In both the scenarios, personalised recommendations are used using the Recommendation Engine (which we will understand later). The important point to note is that both customers and the business benefit from such personalised recommendations. How? Customers find the right products for them easily (without hassle) and thus overall customer satisfaction increases. Businesses benefit from increased customer loyalty, less drop-out, successful cross-sell and upsell, and ultimately, more revenue!
Whether you are using e-commerce platforms to purchase products or watching movies on OTT platforms, you might have been aware that recommendation technology is used to provide personalised content and offers. Recommendation engines are used in various businesses to enhance the interaction of customers with the platforms and are widely used applications of big data and machine learning. Among the most known applications is Netflix’s recommendation engine which provides us with personalised movies to watch and Spotify’s list of recommended songs when we listen using their app.
Excited to learn how these personalised recommendations are generated? Read on
What are Recommendation Engines?
Recommendation Engines (or Recommender Systems) are algorithms that are used to produce personalized recommendations of information/ solutions/ products to users. In this world with a plethora of products and information, if th
e right products & information are recommended to the right users at the right time, businesses & customers can benefit tremendously. Recommendation Systems use historical data from customers like purchase data, cookie data, other psychological and behavioural data. The algorithms also create micro-segments of customers with similar interests & purchase behavior. The best part is, the algorithms are machine-learning-based, as more data becomes available, Recommendation Systems learn on their own and improve their performance.
How do Recommendation Systems work?
Recommendation Systems use a User-based- collaborative filtering technique. The main idea behind this method is that users with similar characteristics share similar tastes. User-Based- Collaborative Filtering is a memory-based method that uses an entire user-item database to generate a prediction. Let us explore with the help of a problem statement how Recommendation Systems exactly work -
- Problem statement: Given transaction-level data that does not have customer data who are buying the products, we need to recommend n products that can be sold along with another product.
- Challenges Faced by NeenOpal: The effectiveness of any data analytics solution depends on the quality and granularity of the raw data. The same is the case for recommendation engines – to build an accurate recommender system, historical user purchase data is needed. However, we all know that good quality data is not always available. We faced the same issue – we could not access good quality user-level transaction data. However, with our experience of dealing with such situations, domain expertise in Recommendation Systems & out-of-box thinking, we were able to design an accurate recommender system for our client. Interested to know how we cracked the problem? Read on!
- Association Rules and Apriori Algorithms: Before diving into how we helped one of the biggest FMCG companies in India with Recommendation Systems, let us first understand a few important terms.
To perform Market Basket Analysis, Association rules become handy as they identify relationships between various items from large data. Association rules is a simple technique that captures buying patterns which consists of an antecedent (if) and consequent (then). An item found in the transaction data is an antecedent and any item present along with antecedent is a consequent.
To generate these rules we use the Apriori algorithm which gives us various metrics for a rule as discussed below.
Rules are used to identify relationships between products from huge data. These rules do not find an individual’s preference, but rather extract relationships between a set of products for every distinct transaction.
Various metrics used to evaluate rules are:
1. Support: This metric helps in finding out the frequency of an item set in the transaction dataset. We can consider a minimum support value for rules. Consider an example, we want to consider product combinations which occur no less than 50 times in 5000 transactions, i.e., support=0.025

2. Confidence: This measure tells how much confident our rule is, to have consequent given that antecedent {X1} is already in the cart. Precisely, confidence is nothing but the measure of likeliness of consequent {X2} given the antecedent{X1}.
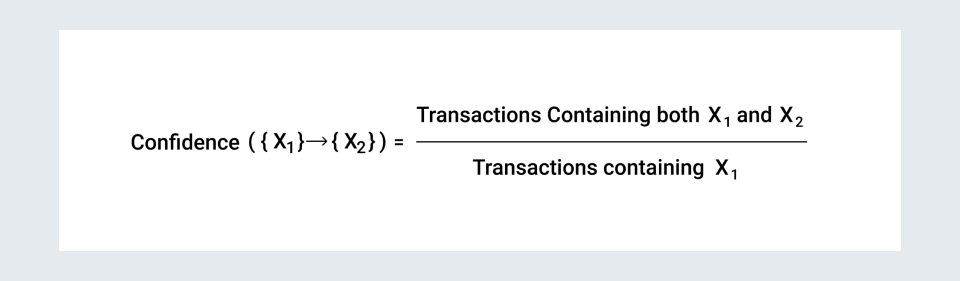
3. Lift: Lift controls for the support of consequent while calculating confidence for antecedent {X1} and consequent {X2}.

Logically, the lift is an increase in the chances of being present on the cart over the odds of on the basket without knowing its existence of .In spite of having high confidence value, a value of lift 1 indicates that odds of occurrence of the consequent do not increase by having an antecedent on the cart and vice versa. The large value of lift boosts the likeliness of buying if the customer has bought.
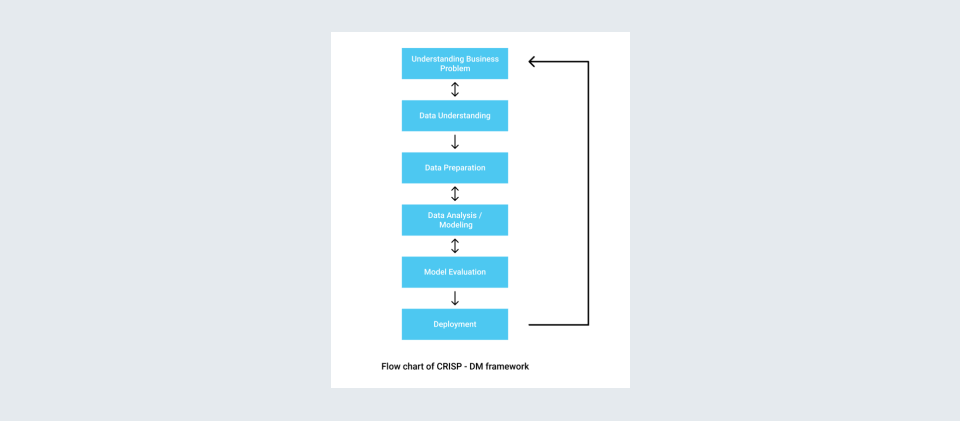
How to Solve This Problem: Consider a cosmetic brand that sells a wide range of cosmetic products. They need to understand the best products that can be bought in combination with the one customer is buying. By finding a solution to this problem, they can recommend these products to a customer to increase sales and revenue. To start off, what we have is a daily-level transaction data with millions of rows for a month. We follow the CRISP-DM framework (Cross Industry Standard Process for Data Mining) for solving a business problem, data preprocessing, data cleansing, and transformation of data are performed to ensure the dataset is ready to be used for model
We used the Apriori algorithm to generate top n consequents for an antecedent based on the lift and minimum support value. At this step, we have product level recommendations, but we still need to account for various other factors which are not taken care of by association rules. So, after incorporating this data and adding various parameters to transactional level data, we transform data in such a way that it consists of a single row for transactions with products as columns and values as 0 and 1 showing whether it was bought or not in the transaction. We are training the model on 67% of the data and testing the model on rest 33% of the data. By using the stratify parameter we maintain the proportion of the data as in the original data frame. For example, if the ratio of an item set is 40:60 in the original data frame, we can see that for every 100 samples we will have data of item set in the ratio 40:60. After that training data is under-sampled i.e., samples having and {B} are maintained in proportion with samples having {A} and {other products}.
Under-sampling is performed next basically to balance the class distribution that has majority data from a single class, it is used to maintain the samples from minority class and majority class in proportion in the training dataset. If there are hundreds, thousands, or millions of samples in class M for a sample in class N, then class N is minority class and class M is majority class. Here, we are considering two classes class 1 and class 0, for example, while considering an antecedent {A} and consequent {B}, class 1 is the transactions containing both these items and class 0 is transactions containing {A} and any other items.
We used XG Boost classifier algorithm in this scenario which is a binary classification algorithm, city-level data is fed into the algorithm and number of models generated for each city are Number of antecedents* n number of consequents. For every antecedent, we cannot have exactly n number of consequents due to various constraints (For ex: Minimum support value) and unavailability of consequents bought along with antecedents in the transaction-level data. Algorithm provides us with the probability of selling both {A} and {B} in combination, and this model data is saved into a pickle file, which is used to save model characteristics and schema.
As this is a classification problem, we have evaluated the model and tuned the parameters using recall, precision, F1-score, and bunch of other evaluation metrics. All these metrics are evaluated using confusion matrix.
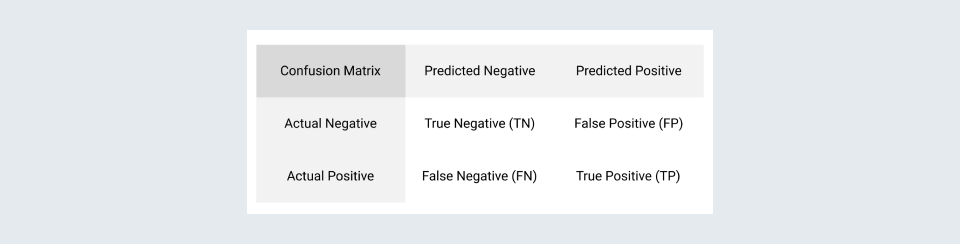
Out of all the predictions made by model, precision gives us how many of them were correct

And Recall tells us how many predictions were identified correctly by the model.

Furthermore, some rules are defined for generating output file like, if we don’t have enough consequent combinations for any antecedent, we recommend top products from that city as consequents. For every Region/City we fetch the top n products and recommend them as consequents using various metrics (Ex: Lift) and recommend them with Generic Antecedents for each store in the city to recommend the items that go into the cart with the antecedents for which we have not performed the above process due to insufficient data or new products.
The training and prediction codes are independent, as we are the storing the model information for each city, antecedent and consequent combination as pickle files, once the training is done on the historical data, prediction can be run multiple times if required.
Some of the features that we have considered include Seasonality such as Day of Week, Month, Marriage season, Events such as Holidays, Festival and store level characteristics along with the lift scores from the Apriori algorithm.
Benefits of customized Recommendation Systems
1. A recommendation engine can significantly boost revenues and increase the average transaction value.
2. It can have positive effects on the user experience, thus translating to higher customer satisfaction and retention.
3. Increase the number of products per transaction, when customers are shown preferences based upon their interest, it is more likely that they will add items to their purchase.
Conclusion
In recent years, recommendation systems have proliferated to various sectors and they are being used to a great extent especially in consumer-centered companies. For example, Netflix’s recommendation engine is valued at $1 billion per year, which is why building a suitable recommendation engine for your business can keep you miles ahead than your peer group!
