

Artificial Intelligence is changing different industries, making them more aligned with market standards. Unfortunately, the tech is not always perfect.
While you are training your data model, you see 95% accuracy, but it still fails in production. This leads to false-positive spikes, blocked legitimate transactions, and no alerts. Yet, no one owns the fix.
As per research statistics, 46% of AI models never reach production, and 40% of them degrade within the same year.
This isn’t a rare failure mode; it’s the default outcome when deployment is treated as a handoff rather than a discipline.
This article breaks down exactly why AI model deployment challenges in production occur, where the lifecycle breaks, and how to fix it with a framework that holds up in real enterprise environments.
Why AI Models Fail in Production: The Reality Gap
There’s a structural mismatch between how models are built and where they are expected to perform.

Training environments are controlled. Production environments are not.
In development, data is clean, curated, and static. In production, data pipelines shift, schemas evolve, upstream systems change behavior, and user patterns drift, often without warning. The model doesn’t get notified.
Most ML teams optimize for validation metrics. Very few define what success looks like in production before deployment. As a result, teams end up retraining models repeatedly, chasing Marginal accuracy gains that exist, but the real issue lies elsewhere, either in the pipeline, infrastructure, or integration layer.
We’ve seen teams retrain the same model five times before realizing the feature pipeline was silently breaking.
Enterprise constraints amplify this gap. Security reviews delay deployments. Legacy systems introduce latency. Governance requirements slow iteration. Procurement cycles limit infrastructure choices.
This is not a modeling problem. It’s a systems problem. And treating it as anything else guarantees failure.
The AI Deployment Lifecycle: Know Where Things Actually Break
The lifecycle runs: Data → Training → Validation → Staging → Deployment → Monitoring → Iteration. The failures rarely happen within a stage. They happen at the transitions between them.
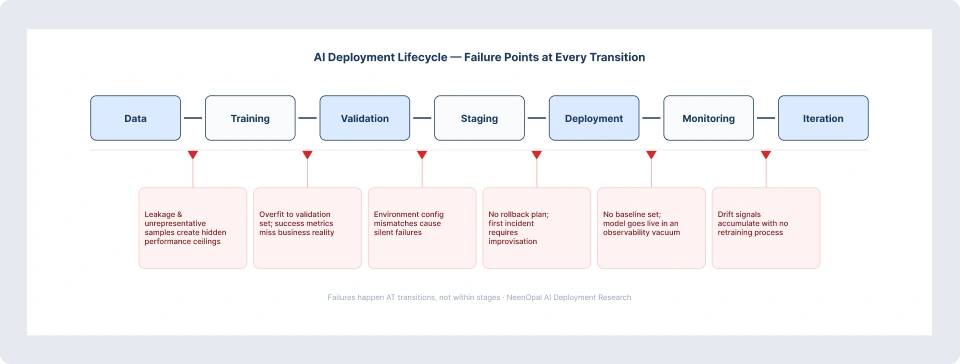
- Data → Training: Leakage, unrepresentative samples, and undocumented feature engineering create hidden performance ceilings. These are one of the most overlooked AI implementation challenges in enterprise that won’t surface until production.
- Training → Validation: Overfitting to the validation set and defining success metrics that don’t reflect the business decision produces misleading benchmarks.
- Validation → Staging: Environment configuration mismatches and missing dependencies mean a model passes validation but fails or behaves differently in staging—one of the critical AI model deployment challenges production teams face.
- Staging → Deployment: Incomplete load testing and no rollback plan mean the first production incident requires improvisation, not execution—highlighting persistent model deployment issues in production.
- Deployment → Monitoring: No baseline is established at deployment. No alerting is configured. The model goes live in an observability vacuum, a recurring theme in AI implementation challenges in enterprise.
- Monitoring → Iteration: Drift signals accumulate with no formal process for acting on them. Retraining is ad hoc, triggered by crisis rather than thresholds. This is one of the most critical AI model deployment challenges production environments must address.
Top AI Model Deployment Challenges
Do you know that only 25% of enterprises scale successfully from pilot to production? It is important to consider common challenges that hinder the possibilities for an AI-driven organization to scale. Here are the top AI model deployment challenges that you should be aware of:

1. Data Drift and Data Quality Degradation
The model was trained on last year’s data. It’s now running on today’s reality. Customer behavior has shifted. Product lines have changed. An upstream CRM update introduced missing values in a key feature, which is now null 30% of the time.
This is data drift in production ML, and it’s the most common failure mode.
There are two types:

- Covariate drift: Input distributions change
- Concept drift: The relationship between inputs and outputs changes
Both degrade performance silently. Without monitoring, drift is invisible until business metrics deteriorate.
2. Lack of Model Monitoring and Observability
In traditional systems, teams monitor uptime, latency, and errors. In ML systems, the equivalent signals are often missing. We observe that no one is talking about prediction distributions, feature stability, and ground truth feedback loops
So when performance drops, it surfaces as a business issue, declining conversions, and inaccurate forecasts long before it’s identified as a model issue.
By the time the root cause is found, weeks are lost. Monitoring is not a “nice-to-have.” It’s the only way to make models observable in production.
3. Infrastructure and Scalability Mismatches
A model that runs in 400ms on a laptop doesn’t behave the same under production load. Concurrency increases. Memory constraints emerge. Latency requirements tighten. Batch pipelines are forced into real-time contexts. GPU availability differs between training and production. Containerization gaps surface. This is where the ML-to-engineering handoff typically breaks. The issue isn’t the model; it’s that the environment it was built in doesn’t resemble where it’s deployed.
4. Integration with Legacy Enterprise Systems
Enterprise AI doesn’t operate in isolation. It integrates with CRMs, ERPs, data warehouses, and reporting systems, each operate with its own constraints.
APIs change. Data formats vary across business units. ETL jobs fail silently. Middleware introduces latency. What was designed as a real-time decision system becomes a delayed approximation.
The integration layer is often the most underestimated and most fragile component of deployment.
5. Ownership Ambiguity Across ML, Engineering, and Business
Who owns a deployed model? In most enterprise organizations, the answer is nobody, clearly. Data scientists built it. Engineers deployed it. The business unit consumes it. When performance degrades, each team assumes the other is responsible, and issues go unresolved for weeks. This isn’t a people problem, but it’s a structural gap. Teams must clearly define who monitors, alerts, rolls back, and approves retraining; otherwise, no one takes accountability.
6. No Deployment Lifecycle Planning
Most teams treat deployment as a one-time event. They build the model, deploy it, and move on. What’s usually missing isn’t the model itself; it’s everything around it that makes it reliable at scale. There’s no clear versioning strategy, so no one’s fully sure which model version is driving which outcomes. There’s no rollback mechanism in place, which means when something breaks, you’re scrambling instead of switching back safely. A/B testing frameworks are rarely set up, so changes go live without being properly validated in real conditions.
Retraining? It happens, but not on a defined schedule—usually only when performance drops enough to cause concern. And almost no one talks about deprecation policies, so outdated models just linger in the system longer than they should.
These gaps are a classic example of enterprise AI adoption challenges. The focus is heavily on building the model, but not on operationalizing it.
A Practical Framework for Resolving AI Deployment Failures
If you move with a "set up-experiment-learn" mindset, you can resolve the AI challenges much faster because fixing model deployment issues in production requires discipline. Here is a sequential operationalization that you can do:
Step 1: Define Production Success Metrics Before Deployment
Before a single line of deployment code is written, define what “working” looks like in business terms. Not accuracy. Not F1 score. What decision does this model support, and what is the acceptable error rate for that decision? These definitions become the monitoring baseline and the standard against which retraining decisions are evaluated.
Step 2: Build Deployment-Ready Pipelines, Not Just Models
The deliverable from an ML project should be a reproducible, versioned pipeline, versioned data, versioned features, versioned model artifacts, and fully documented dependencies. If a data scientist’s departure would make the model undeployable or unreproducible, the pipeline is not production-ready.
Step 3: Instrument Monitoring from Day One
Monitoring should be deployed with the model, not added after the first incident. Minimum viable monitoring includes prediction distribution, input feature distributions, system latency, and throughput, and, where ground truth is available, it measures the outcome tracking. Alert thresholds should be set at deployment. Alert owners should be assigned explicitly.
Step 4: Establish MLOps Ownership With a Defined RACI
You need clear ownership across ML, engineering, and the business. Not loosely aligned responsibilities, but an actual, explicit ownership. One of the most practical ways to address this (and a key part of overcoming enterprise AI adoption challenges) is to define a model owner role. Without this role, ownership defaults to nobody, which indeed is the most expensive accountability structure in enterprise AI.
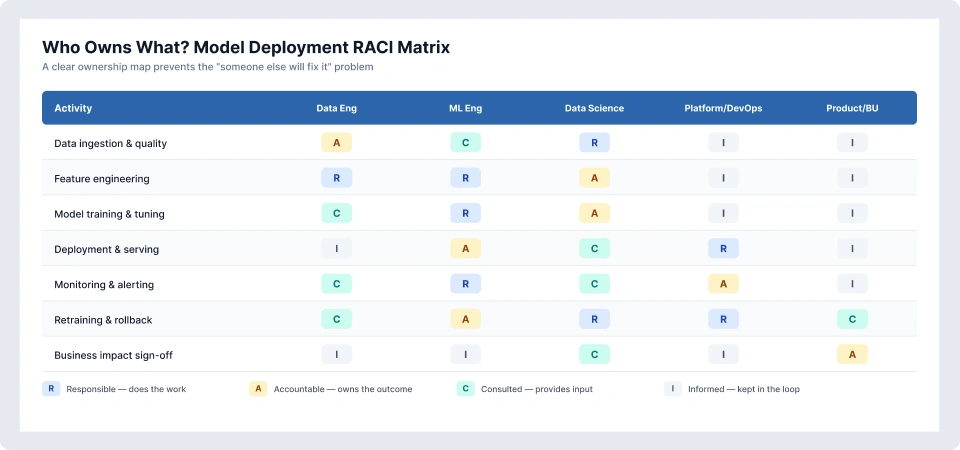
Step 5: Build a Continuous Retraining Strategy Before You Need It
Retraining should be a scheduled, tested process and not a crisis response. Define retraining triggers: drift thresholds, time-based cadence, and business event triggers. Build and validate the retraining pipeline in staging before the first production drift event forces an unplanned retrain under pressure.
What Consistently Works in Enterprise AI Deployments
Across engagements with mid-market and enterprise teams in healthcare, financial services, and retail, a small set of practices separates teams with reliable production AI from those cycling through repeated deployment failures.
The teams with the most durable deployments treat the model as a product, not a project. They have roadmaps, designated owners, and defined release cycles. The model doesn’t end at go-live, it has a lifecycle that extends through monitoring, iteration, and eventual retirement.
The most underinvested area in enterprise ML is consistently the feature store. Teams rebuild features from scratch for every model, creating undocumented drift vectors they don’t track. A centralized, versioned feature store reduces this risk substantially and accelerates time-to-deployment for every subsequent model.
Shadow mode deployment is one of the most effective risk mitigation techniques available, which runs a new model in parallel without acting on its output. Teams that adopt it routinely catch integration failures and drift issues before they affect live decisions.
Finally, the most expensive enterprise AI failures share one defining characteristic is the absence of a tested rollback plan. Every production deployment should have an explicit, rehearsed procedure to revert to the previous model version. The teams that rehearse rollbacks rarely need to use them urgently.
When to Bring in AI/ML Deployment Experts
Some deployment challenges are solvable with internal process changes and the right tooling investment. These issues reveal a structural gap. Consequently, teams lack MLOps practices, monitoring, deployment discipline, and proper versioning that often need outside expertise to fix them.
If your team is experiencing repeated deployment failures, cannot trace performance degradation to a root cause, or has models in production that no single person fully understands or owns, those are signals that the deployment architecture requires attention. A second pair of eyes on your deployment architecture often surfaces the issues that are hardest to see from the inside.
If your team is working through deployment failures or building out an MLOps practice, we’ve seen most of these patterns before. → Talk to our AI deployment team.
Frequently Asked Questions
1. Why do AI models fail in production even when they perform well in testing?
Models are trained on historical, controlled datasets, while production environments are dynamic and unpredictable. Data distributions shift, upstream systems change, and user behavior evolves in ways you didn’t model for. On top of that, enterprise realities, including latency constraints, infrastructure limitations, and legacy integrations, introduce failure modes you’ll never see during development.
2. What is the AI deployment lifecycle, and where does it typically break down?
In practice, the lifecycle runs through data preparation, training, validation, staging, deployment, monitoring, and retraining. Sounds structured on paper, but the real cracks appear in the transitions. Teams skip proper load testing, so production behaves very differently under real traffic. And the biggest gap? Monitoring to iteration. There’s no defined retraining loop, so models quietly degrade over time.
3. What are the most common ML model deployment challenges in enterprise environments?
Common challenges include data drift, lack of monitoring, infrastructure mismatches, legacy system integration issues, ownership ambiguity, and absence of lifecycle planning. While tools can address technical issues, organizational misalignment remains the most persistent blocker.
4. How should teams monitor machine learning models in production?
You’ll see the same patterns across organizations: data drift, weak or missing monitoring, infrastructure mismatches, and constant friction with legacy systems. Add to that unclear ownership and no real lifecycle planning. Tools can solve parts of the technical problem—but most failures come down to misalignment between teams. That’s why these aren’t just technical gaps; they’re deeply rooted enterprise AI adoption challenges.
5. What is data drift, and how does it affect production AI models?
Monitoring needs to go beyond system uptime. You should be tracking prediction outputs, feature distributions, and system performance metrics, and wherever possible, validating against actual outcomes. But here’s where most teams fall short: they don’t define thresholds upfront. There’s no clear signal for “this needs attention.” And even when there is, ownership isn’t clear.
