

A win-loss platform is not a typical SaaS product. Every tenant is collecting sensitive competitive intelligence about their deals, and in many cases, those tenants are direct competitors of each other. The architectural decisions that work for a project management tool or a help desk platform break down quickly under these requirements.
This guide walks through how to design a multi-tenant SaaS architecture specifically for win-loss analysis platforms. It covers three areas that generic guides consistently miss:
- Data Isolation: Engineering separation that earns enterprise trust when tenants are competitors.
- Survey Pipeline Automation: Collecting and routing responses from external, unauthenticated buyers at scale.
- Dual Reporting Architecture: delivering per-tenant dashboards and cross-tenant benchmarks from a single data layer.
Everything covered here is based on production delivery experience as an AWS SaaS Competency Partner. This is not a theoretical framework. It is the architecture we build for win-loss platform clients, and the reasoning behind decisions that generic SaaS guides do not address.
Already past the architecture decision? Talk to NeenOpal about building your win-loss platform on AWS.
Why Win-Loss Platforms Have Unique Multi-Tenancy Requirements
1. Competitor Data Sensitivity:
The tenant isolation challenge in win-loss platforms goes well beyond standard GDPR compliance. When Tenant A and Tenant B compete in the same market, a data leakage event is not just a regulatory failure. It is a catastrophic trust event that can destroy the product entirely.
Row-Level Security is a necessary baseline, but it is not sufficient on its own at scale. The isolation requirement is elevated from 'logical separation is acceptable' to 'zero cross-tenant data exposure under any failure mode.' This specific pressure does not appear in generic SaaS architecture guides because those guides assume tenants are independent businesses with no relationship to each other. Win-loss platforms cannot make that assumption.
The practical consequences of getting this wrong include:
- A configuration error that exposes one tenant's win data to a rival is not recoverable through an apology. Both customers leave.
- Row-Level Security policies applied only at the ORM layer can be bypassed by service-level queries using privileged database roles.
- Caching layers that do not carry tenant context can serve one tenant's aggregated data to another under high-load conditions.
The architecture must treat competitor data sensitivity as an existential requirement, not a compliance checkbox.
2. The Dual Reporting Requirement:
Win-loss platforms must simultaneously deliver two very different types of reports:
- Per-Tenant Reporting: Your win rate by quarter, your top deal loss reasons, your competitive record against named competitors. This layer requires strict isolation.
- Cross-Tenant Benchmarking: How does your win rate compare to the industry average? What are the top objection categories across all B2B SaaS companies in your segment? This layer requires aggregated views across all tenant data.
These two requirements create opposing architectural pressures. Standard multi-tenancy guides address the first requirement well and ignore the second almost entirely. Designing both in the same data layer is not a default outcome of following generic advice. It requires deliberate schema design and a separate aggregation pipeline with specific privacy controls.
3. External Data Collection Complexity:
Unlike most SaaS products, win-loss platforms collect data from people who are not users of the platform. Survey respondents are buyers, lost prospects, and churned customers of the tenant's business. This creates a set of engineering requirements that standard multi-tenancy guides assume away entirely:
- Inbound data arrives from unauthenticated external sources, not from credentialed platform users.
- Each response must be validated and routed to the correct tenant before it touches any shared storage.
- The pipeline must handle variable response latency, since a buyer may submit a survey days or weeks after receiving the link.
- Misrouted responses carry competitive intelligence consequences, not just data integrity errors.
Standard SaaS multi-tenancy guides assume all incoming data originates from authenticated tenant users. Win-loss platforms break this assumption entirely, and the pipeline must be designed to account for it from the start.
Choosing the Right Tenancy Model for a Win-Loss Platform
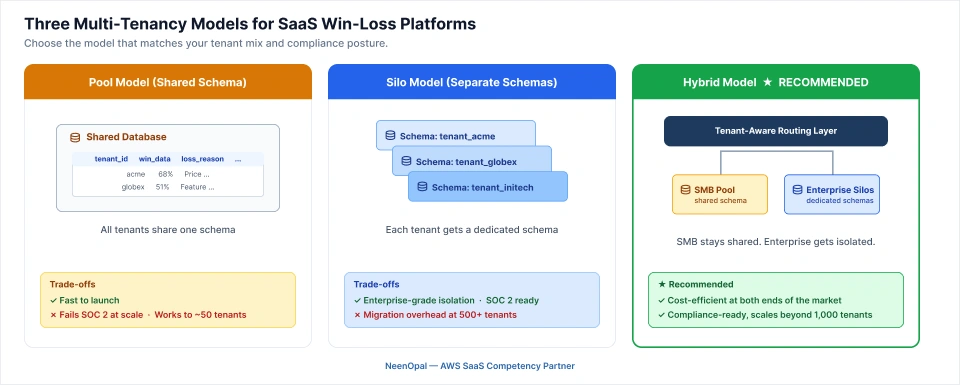
There are three models to evaluate. The right answer depends on where you are in product maturity and who your target customers are.
1. Pool Model (Shared Schema): When It Works and When It Fails
The pool model employs a shared database structure that includes a tenant_id column on each table. It is the default starting point for most SaaS companies due to its low-cost, speed of implementation, and ease of onboarding new clients.
For early-stage win-loss platforms, the pool model is reasonable under specific conditions:
- Fewer than 50 tenants with no enterprise compliance requirements.
- Interview datasets that are small enough that shared table performance is not a concern.
- No tenants that are direct competitors of each other, which reduces the isolation stakes.
The failure modes emerge predictably as the platform scales. At 200 or more tenants, enterprise clients demanding SOC 2 or HIPAA alignment will find that a shared schema cannot demonstrate the isolation guarantees auditors require. As one tenant's interview dataset grows to millions of rows in a shared table, query performance degrades for every other tenant on that table.
For win-loss platforms targeting enterprise buyers, the pool model is a technical debt trap. It looks entirely reasonable at launch and becomes an architectural crisis at 100 tenants.
2. Silo Model (Separate Schemas Per Tenant): The Enterprise-Grade Choice
The silo model provisions a dedicated PostgreSQL schema for each tenant using CREATE SCHEMA. The advantages over the pool model are significant for enterprise-focused platforms:
- Stronger Isolation Guarantees: Each tenant's data is physically separated, not just filtered by a column value.
- Shorter Compliance Conversations: Demonstrating isolation to a SOC 2 auditor is straightforward when schemas are separate.
- Higher Performance Ceiling: Per-tenant queries do not compete with other tenants' datasets on shared table storage.
- Cleaner Right-to-Erasure Implementation: Deleting a respondent's data from one schema does not require touching any other tenant's records.
The operational cost is real. Schema migrations must run across every tenant schema. At 500 tenants, a migration is a coordinated infrastructure operation requiring orchestration, rollback planning, and monitoring. Onboarding automation must also provision and validate each schema reliably at signup without manual intervention.
3. Hybrid Model: The Recommended Architecture for Win-Loss at Scale
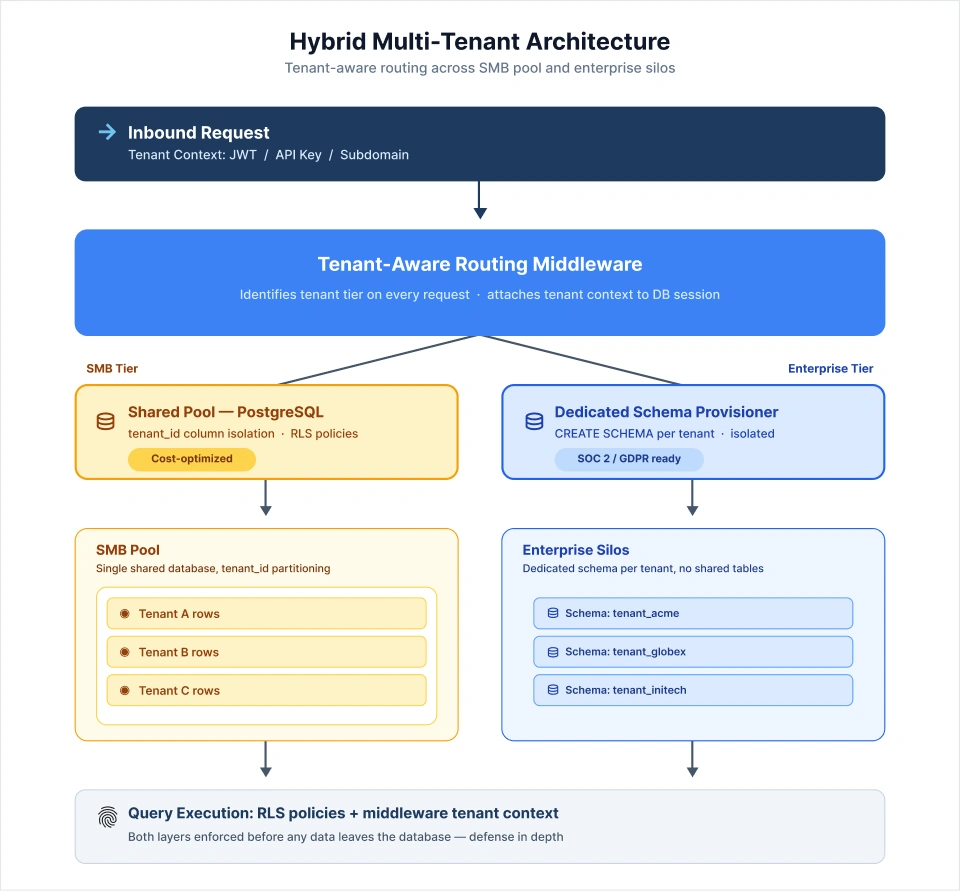
The hybrid model combines both approaches with a routing layer that determines which schema handles each request:
- SMB Tenants: Placed in a shared pool where cost efficiency and adequate performance for smaller interview datasets make the pool model appropriate.
- Enterprise Tenants: Provisioned with dedicated schemas that provide full isolation, compliance demonstrability, and performance headroom.
- Routing Layer: A tenant-tier-aware middleware that identifies the tenant and directs queries to the correct schema on every request.
This is the architecture NeenOpal recommends for win-loss platforms expecting a mix of SMB and enterprise clients. The economic model works at both ends of the market without forcing a single compromise.
The implementation complexity is concentrated in the routing layer. It must carry tenant context throughout all layers of the stack, including the API, transformation services, cache layer, and reporting queries. A routing failure anywhere in the middle of the stack might result in data integrity issues that are difficult to identify and costly to correct.
Automating the Survey and Interview Data Pipeline
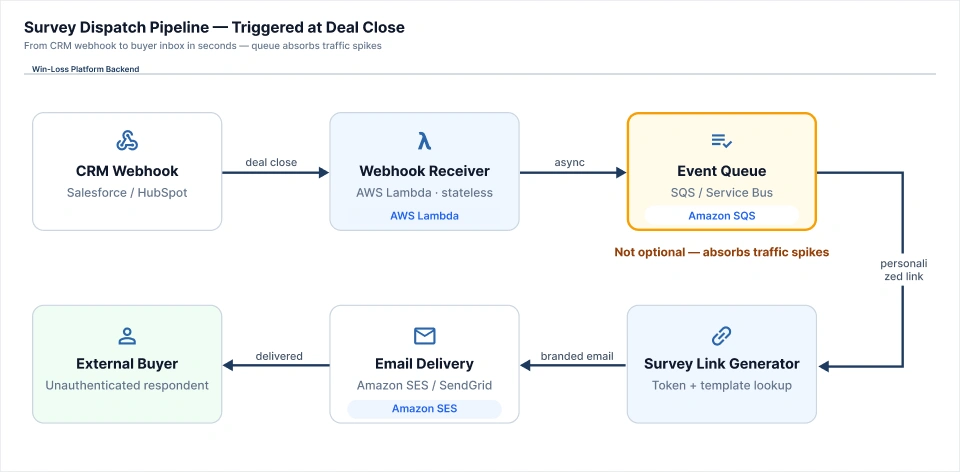
The survey pipeline is the layer that makes a win-loss platform function as a product rather than a database. It is also the layer where most of the domain-specific engineering complexity lives, and the layer that no generic SaaS architecture guide covers.
1. Survey Dispatch Automation:
When a deal closes or churns in the tenant's CRM, a webhook event triggers the survey dispatch pipeline. The sequence of steps is:
- Receive the CRM webhook from Salesforce or HubSpot.
- Identify the originating tenant from the webhook source and authentication token.
- Look up the survey template configured for that tenant, since each tenant may have customized questions, branding, and question logic.
- Generate a personalized survey link with an embedded session token that encodes the deal and tenant identifiers without exposing internal database IDs.
- Deliver the link via email or in-app notification using the tenant's configured delivery method.
The engineering components behind this flow are:
- Webhook Receiver: Built on AWS Lambda or Azure Function, stateless and independently scalable.
- Event Queue: SQS or Azure Service Bus between the receiver and downstream processing, absorbing traffic spikes at deal close events.
- Survey Link Generator: Handles session token creation, template lookup, and personalization.
- Email Delivery: Amazon SES or SendGrid, using tenant-configured sender domains where possible.
The queue between the webhook receiver and the downstream processing steps is not optional. Deal close events are not evenly distributed throughout the day. The queue absorbs volume spikes and provides the retry capability that a direct synchronous call cannot.
The survey pipeline architecture described above is what NeenOpal engineers for win-loss platform clients. If you are building this layer, our team has done it in production. Talk to a SaaS Architecture Engineer.
2. Response Ingestion and Tenant Routing

When an external buyer submits a survey response, the ingestion pipeline must complete four steps before any data reaches persistent storage:
- Token Validation: Confirm the session token is valid, identify the deal and tenant associated with the response, and reject any request with an invalid or expired token.
- Field Extraction: Pull structured fields from the response payload, including win or loss reason, competitive mentions, pricing objection flags, and any custom taxonomy fields the tenant has configured.
- NLP Classification: For AI-powered platforms, route open-text responses through the classification service to assign standardized categories and sentiment scores.
- Tenant Schema Write: Write the enriched record to the correct tenant schema or partition only after all prior steps have completed successfully.
The routing validation must be a hard gate, not a soft filter applied after the fact. A misrouted survey response occurs when a customer mentions a competitor in the wrong tenant's dataset, resulting in a data integrity failure with direct competitive intelligence effects. Build it as an enforced pipeline step rather than an application-layer check.
3. Transformation and Enrichment Layer
Raw survey responses require transformation before they are useful in a reporting layer. The transformation operations cover four categories:
- Field Normalization: Mapping open-text reason codes to a standardized taxonomy that makes cross-response reporting meaningful.
- Sentiment Scoring: Assigning sentiment classifications to qualitative open-text fields for aggregate trend reporting.
- Competitor Entity Resolution: Normalizing variant spellings and abbreviations to a canonical competitor name so that 'Salesforce', 'SFDC', and 'SF' all resolve to the same entity in reporting.
- CRM Metadata Enrichment: Pulling deal size, stage, region, and rep details from the CRM record associated with the deal to enable segmented reporting.
NeenOpal architects the transformation layer as a stateless service that reads records from the event queue, processes them, and writes enriched records downstream. The stateless design allows the transformation service to scale independently from the ingestion layer during periods of high response volume.
4. Real-Time vs Batch Processing Decisions
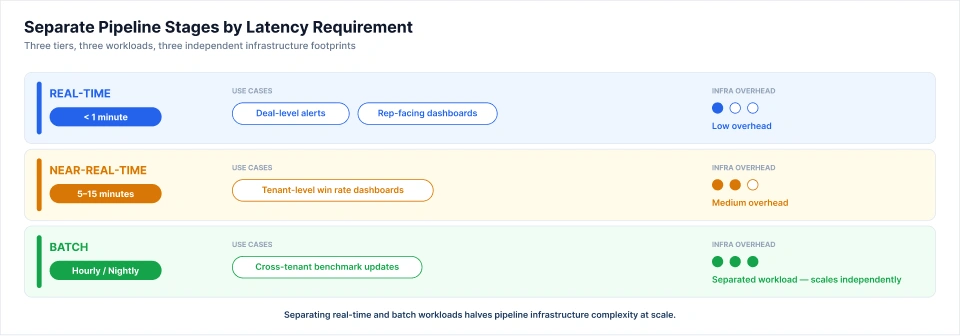
Not every pipeline stage requires the same latency, and over-engineering for real-time adds infrastructure complexity without meaningful benefit to the end user. The recommended approach is to separate pipeline stages by latency requirement:
- Real-Time Processing: Deal-level alerts and rep-facing dashboards, where the value of a win-loss signal diminishes rapidly after the deal closes.
- Near-Real-Time Processing (5 to 15 minutes): Tenant-level win rate dashboards, where a short lag is acceptable but hours would feel stale.
- Batch Processing (Hourly or Nightly): Cross-tenant benchmark updates, where aggregates do not need to reflect the last hour of responses.
Separating the real-time and batch workloads halves the infrastructure complexity of the reporting pipeline and reduces cost meaningfully at scale without degrading the user experience that matters most.
Automated Reporting Architecture: Per-Tenant and Cross-Tenant
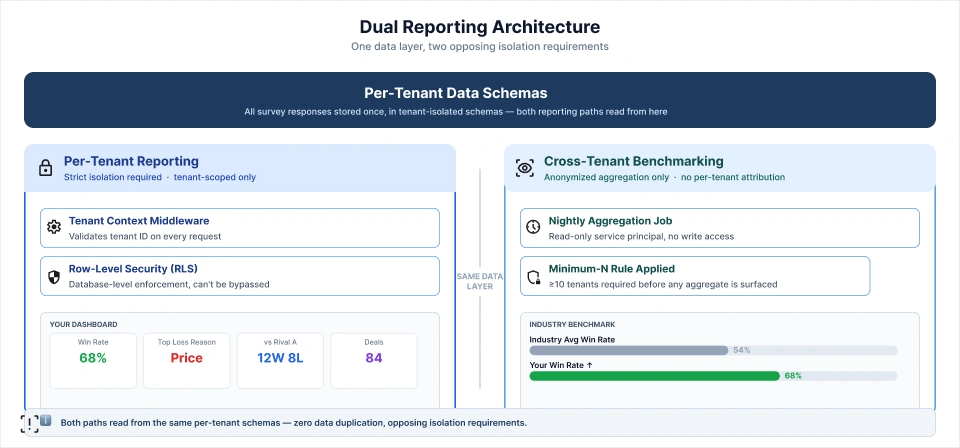
1. Per-Tenant Reporting Layer
Each tenant dashboard displays data scoped entirely to their own records. The scope of per-tenant reporting includes:
- Win rate by quarter, sales rep, and deal segment.
- Top loss reasons ranked by frequency and by deal value lost.
- Competitive win and loss records against named competitors.
- Deal cycle analysis comparing won and lost deal timelines.
The architectural requirement is that every query filling a dashboard be tenant-scoped at both the data and application layers. Application-layer filtering is insufficient as a standalone control because a query optimization, a cache problem, or a misconfigured ORM relationship can all result in cross-tenant data exposure when the only isolation is in the application code.
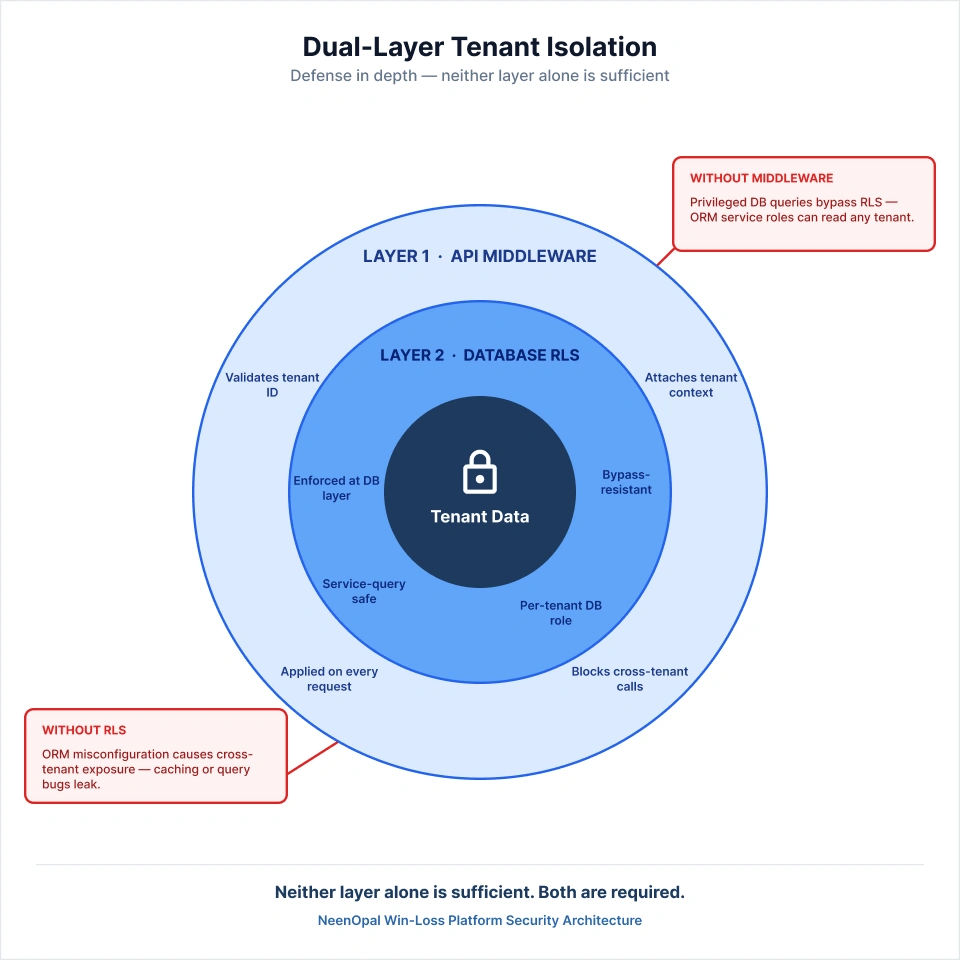
NeenOpal enforces tenant isolation at two independent levels:
- Database Level: Row-Level Security policies on per-tenant schemas or tables, applied using the tenant's database role context.
- API Level: Tenant context middleware that validates the tenant identifier on every inbound request and attaches it to the database session before any query executes.
Both controls are required. This dual-layer enforcement is part of a broader modern data stack for SaaS analytics approach that NeenOpal applies across all reporting architectures. RLS without middleware can be bypassed by service-level queries using privileged database roles. Middleware without RLS is vulnerable to application-layer errors. Neither layer alone is sufficient.
2. Cross-Tenant Benchmarking Layer
The benchmark reports aggregate across all tenant data to produce industry comparisons, but they must never expose which specific tenant contributed which data point. The architecture uses a separate aggregation pipeline with the following design:
- Service Principal Access: A read-only cross-schema service principal that can read from all per-tenant schemas, with no write permissions and no access to identifiable tenant metadata.
- Minimum-N Rule: A configurable threshold; for example, ten tenants minimum, below which no aggregate is surfaced in the reporting layer. This prevents reverse-engineering of individual tenant data from small-sample benchmarks.
- Separate Benchmark Schema: Aggregated and anonymized results are written to a shared schema that contains no per-tenant attribution. This is the only schema the benchmark reporting API reads from.
- Nightly Pipeline Cadence: The aggregation job runs on a scheduled cadence, separate from the real-time per-tenant reporting path, with no shared compute resources.
The minimum-N rule is the critical privacy control in this layer and must be configurable by the platform operator. The required level varies based on market sector and total renter count. A platform serving 30 tenants in a specific vertical cannot use the same threshold as one serving 3,000 tenants in a broad market.
3. Automated Report Distribution and Alerting
Win-loss platforms deliver their highest value through proactive insight delivery, not through dashboards that users remember to check. The automated reporting layer handles three delivery patterns:
- Weekly Digest Emails: Scoped to each tenant's data, formatted using tenant-specific templates, and delivered on a scheduled cadence.
- Threshold-Triggered Alerts: Sent when a tenant's win rate drops below a configured level or when a specific competitor starts appearing more frequently in loss reason data.
- Deal-Level Alerts: Triggered when a competitive pattern is detected in a newly processed survey response, delivered to the relevant sales rep or manager.
Alert triggers use the same event queue infrastructure as the survey ingestion pipeline, ensuring consistent delivery reliability without building a separate notification system. The same pattern used in Power BI automation for scheduled report distribution applies here, with tenant scoping applied at every layer of the output generation and delivery process.
Scaling Considerations: From 50 to 5,000 Tenants
1. Database Scaling Patterns:
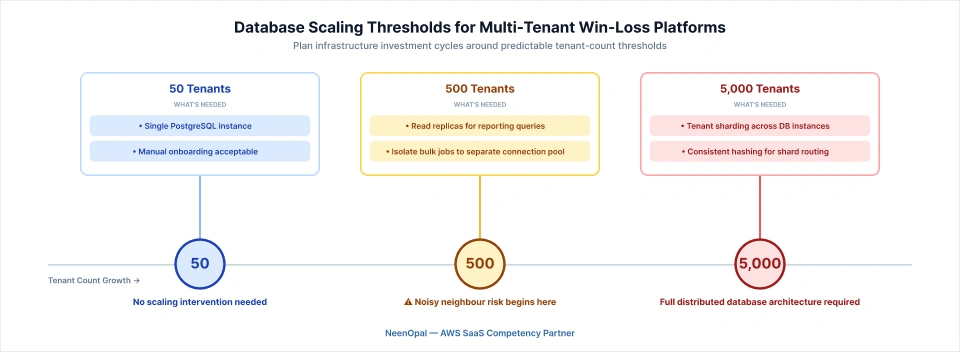
The scaling requirements change at predictable tenant count thresholds:
- 50 Tenants: A single PostgreSQL instance handles the full workload without issue.
- 500 Tenants: Read replicas specific to the reporting workload are necessary to prevent reporting queries from clashing with write operations on the ingestion channel.
- 5,000 Tenants: Tenant sharding across multiple database instances is required, with a consistent hashing layer directing each tenant to the appropriate shard.
The noisy neighbour problem takes a specific form in win-loss platforms. A tenant running a large historical import or a bulk re-classification job can saturate the shared database I/O in ways that degrade response times for every other tenant.
NeenOpal's approach to cloud-native SaaS infrastructure isolates bulk import and re-classification jobs to a separate connection pool with explicit resource limits, completely separate from the real-time query path. This is a low-cost configuration decision at small tenant counts and a significant operational protection at scale.
2. Onboarding Automation:
Each new tenant requires a sequence of provisioning steps before they can use the platform:
- Schema Provisioning: Creating the dedicated schema (for enterprise tenants) or allocating a pool partition (for SMB tenants).
- Survey Template Seeding: Loading the default question set and branding configuration.
- CRM Integration Configuration: Connecting to the tenant's Salesforce or HubSpot instance and configuring the webhook endpoints.
- Initial User Account Creation: Creating the admin user and sending the onboarding email.
- Benchmark Eligibility Enrollment: Registering the tenant's anonymized data for inclusion in the cross-tenant aggregation pipeline once their dataset reaches the minimum threshold.
At 50 tenants, some steps can be partially manual. At 500 tenants, every step must be fully automated and idempotent. NeenOpal builds tenant onboarding as an idempotent provisioning job where every step is safe to re-run on failure without producing duplicate state or corrupt configuration.
3. Governance and Compliance at Scale:
Enterprise tenants will arrive with compliance requirements that must be built into the architecture before they block a contract. The four requirements that arise most consistently are:
- Data Residency: EU-based tenants require data storage in EU regions. Retrofitting this onto a shared-schema platform at 200 tenants is a multi-quarter engineering project. Building it as a provisioning configuration choice from day one is weeks of work.
- GDPR Right-to-Erasure: Deleting a specific survey respondent's data from a tenant's schema without affecting any other tenant's records. The silo model makes this operation clean and auditable.
- SOC 2 Audit Trail: Every data access event must be logged with tenancy context, timestamp, and user or service principal identification, and the compliance team must be able to query the logs.
- API Rate Limiting Per Tenant: Prevents a single large tenant from overburdening shared infrastructure components during bulk operations or peak survey volume.
Getting compliance architecture right at the start is not a cost; it is an insurance policy. The engineering effort is measured in weeks. The alternative, retrofitting at 200 tenants with enterprise contracts on the line, is measured in quarters.
When to Build vs Buy, and Where NeenOpal Fits
1. The Build vs Buy Decision for Win-Loss Platform Architecture:
Off-the-shelf multi-tenancy frameworks excel at handling the fundamental requirements, such as shared schemas, RLS, tenant ID propagation, and basic authentication scoping. They do not handle the win-loss-specific requirements:
- Survey pipeline design from CRM webhook to per-tenant schema write.
- Competitor data sensitivity as an architectural constraint, not just a compliance concern.
- Dual reporting layer with anonymized cross-tenant aggregation.
- Benchmark privacy controls, including minimum-N rules and configurable thresholds.
Teams that start with a generic SaaS framework and retrofit these requirements typically spend three to six months of engineering time on problems they could have designed away from the start. The signal that expert engagement will be faster than internal iteration is when your architecture discussions keep returning to the same set of questions:
- How do we guarantee isolation when tenants compete with each other?
- How do we build the benchmark layer without exposing individual tenant data?
- How do we route survey responses from unauthenticated buyers to the right schema?
Those are domain-specific problems that generic frameworks leave unsolved.
2. What NeenOpal Delivers:
NeenOpal builds production multi-tenant SaaS architectures as an AWS SaaS Competency Partner. For win-loss platforms specifically, we deliver:
- Data Isolation Architecture: Hybrid pool and silo model with a tenant-aware routing layer, tested under enterprise compliance requirements.
- Survey Dispatch and Ingestion Pipelines: From CRM webhook to enriched per-tenant record, including token generation, NLP transformation, and competitor entity resolution.
- Per-Tenant and Cross-Tenant Reporting Layers: With anonymized benchmarking, configurable minimum-N controls, and double-layer tenant isolation.
- Automated Reporting and Alerting: Weekly digests, threshold alerts, and deal-level notifications using tenant-specific templates.
- Tenant Onboarding Automation: Idempotent provisioning with under 60 seconds from subscription confirmation to tenant-ready state.
- GDPR and SOC 2 Compliance Architecture: Including data residency configuration, right-to-erasure implementation, and audit trail logging.
These are not consulting recommendations. They are engineered systems built on AWS-native services, tested in production, and maintained by the team that built them.
Conclusion
Designing a multi-tenant win-loss SaaS platform requires solving three core challenges: strict data isolation due to competitor sensitivity, accurate ingestion of unauthenticated external survey responses, and a dual reporting layer that supports both tenant-specific and cross-tenant insights.
Early architecture decisions are critical. Planning for scale upfront adds limited effort, while rearchitecting later can lead to significant delays and engineering overhead. Building isolation, data pipelines, and reporting correctly from the start is far more efficient than fixing them later.
Frequently Asked Questions
Q1. What is multi-tenant SaaS architecture?
Multi-tenant SaaS architecture is where a single application instance serves multiple customers while keeping each tenant's data isolated. The three models are shared schema (pool), separate schema per tenant (silo), and hybrid. For win-loss platforms, isolation is especially critical since tenants often compete directly with each other.
Q2. How do you design a multi-tenant database for SaaS?
Choose between three models: pool (shared schema with tenant_id), silo (separate schema per tenant), or hybrid (SMB tenants in a shared pool, enterprise tenants in dedicated schemas). For win-loss platforms, the hybrid model is recommended for any platform expecting a mix of SMB and enterprise clients.
Q3. How do I automate survey data collection in SaaS?
A CRM webhook triggers survey dispatch when a deal closes, the buyer receives an authenticated link, and their response is validated, enriched, and written to the correct tenant schema. The routing validation must be a hard gate before any data reaches storage.
Q4. What is the difference between single-tenant and multi-tenant SaaS?
Single-tenant gives each customer a dedicated deployment with strong isolation but high operational cost. Multi-Tenant serves all customers from one deployment with logical or physical data separation, making it far more scalable. For win-loss platforms, Single-Tenant may suit an early pilot but is not viable at scale.
Q5. How do win-loss platforms store and analyze deal data?
Deal data is stored in per-tenant schemas built from CRM events, survey responses, and interview transcripts, enriched during ingestion with normalized competitor names and sentiment scores. A separate nightly pipeline reads anonymized fields across all tenants to generate cross-tenant benchmarks, with a minimum tenant count threshold applied before any aggregate is surfaced.

